
让我们来聊聊那个洁净室里被刻意回避的真相。当风险投资家们正争先恐后地为下一个双足机器人奇迹砸钱时,一个令人尴尬且残酷的事实正摆在所有人面前:尽管投入了数十亿美元,但这波先进机器人浪潮所产生的实际产出,说得委婉点,充其量只是一个“四舍五入”后的误差。
在最近一份措辞极其直白的简报中,Dyna 的联合创始人 Yang York 像拿手术刀一样精准地剖开了行业泡沫,他描绘出的景象并不乐观。别去管那些机器人跑酷或轻捏鸡蛋的酷炫演示视频了。真正的故事藏在数据里,而这些数据讲述的是一种深刻的脱节。从2022年到2025年,机器人行业疯狂吸纳了超过180亿美元的融资。然而,截至2026年初,它们对现实世界的影响依然微乎其微。
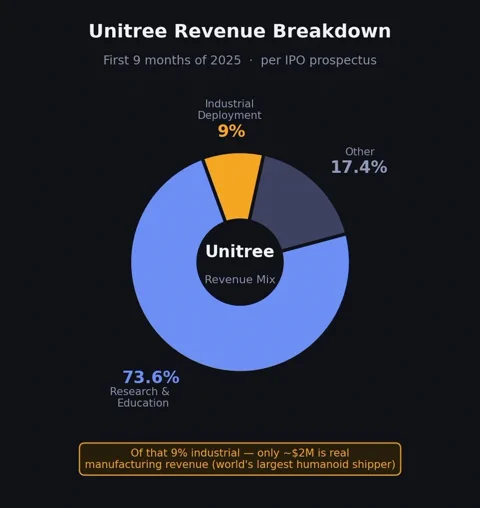
York 点名了硬件繁荣时期的几个标杆。Tesla 的 Elon Musk 在2026年1月的财报电话会议上承认,实际上还没有一台 Optimus 机器人在他的工厂里干过正经活。而作为全球人形机器人出货量最大的公司之一,Unitree(宇树科技)在3月的 IPO 招股书中透露,其收入中高达 73.6% 来自研究和教育销售。实际的工业部署呢?仅占 9%,且其中大部分只是“企业前台和导游”性质的工作。来自“真正”制造任务的收入仅为区区200万美元左右。
这种财务预期与物理现实之间的鸿沟,被 York 称为“泡沫”。这并不是在讨论技术最终是否可行,而是关于时间线的问题。正如他所言:“泡沫就是当前技术能力与人类预期之间的差距,再乘以时间的倍数。”
你的 LLM 类比烂透了,真的
York 论点的核心在于,机器人行业正沉溺于一种错误的“精神供给”——即糟糕的类比。被大语言模型(LLM)指数级增长冲昏头脑的投资者和创始人,正试图将同样的剧本套用到原子世界(Atoms),结果自然是一败涂地。
LLM 能够以光速扩张,是因为它们是纯粹的软件,可以通过互联网瞬间分发给数十亿人。然而,机器人是物理实体。它们会坏,需要维护,还必须在混乱、不可预测的现实世界中摸爬滚打。
另一个更诱人、但也同样存在缺陷的类比是自动驾驶(AV)行业。但即便如此也对不上。汽车即使没有自动驾驶功能,它本身也是一个成熟的产品类别,拥有现成的分发渠道,只等着 AI 的升级。而 York 调侃道,一个没有智能的人形机器人,只不过是“一个重达60磅、拥有28个自由度却毫无用处的铁疙瘩”。它没有内置的用户群,没有可以升级的装机基础。整个行业正试图同时制造应用程序、手机和移动网络。
这意味着机器人的增长曲线不会是 LLM 式的陡峭起飞,甚至也不会是 AV 式的曲线。它将拥有属于自己的“机器人曲线”,而行业拒绝承认这一点,正是其最昂贵的错误。
现代机器人学的三大谎言
York 指出了支撑这个泡沫的三个核心谬误。这些都是行业在兑现一张张九位数支票时,对自己编造的甜言蜜语。
1. 硬件并不等于渠道
最昂贵的误解莫过于认为交付一台物理机器人就等同于建立了一个分发渠道。逻辑是这样的:只要把硬件塞进客户的厂房,剩下的就顺理成章了。这是一个致命的错误。
真正的渠道能创造持续的价值。如果一台机器人在演示完后就因为达不到 ROI(投资回报率)门槛而放在角落吃灰,那你拥有的不是渠道,而是一个非常昂贵的镇纸。York 认为,真正的机器人渠道是一个全栈部署系统:场地评估、任务定义、数据采集、远程调试以及持续更新。
“检验渠道的标准在于,下一次部署是否比上一次更快,”York 写道,“如果不是,那你并没有建立渠道。你只是制造了库存和公关稿。”

2. 你的“基座模型”大部分只是“地基”
第二个错误是对 AI 模型进化方式的误解。机器人领域的讨论目前全部集中在大规模数据集的预训练上。但现代 LLM 的秘诀不仅在于预训练,更在于预训练与特定领域的后期训练反馈(Post-training feedback)之间紧密的迭代闭环。
机器人领域几乎还没开始这个闭环。大多数团队都在强行给模型喂更多的数据,祈祷奇迹般地涌现出某种能力。但如果没有来自现实世界部署的反馈信号——即机器人真的在工厂车间“搞砸了”的数据——模型就无法成熟。机器人领域没有像 LLM 的“困惑度”(Perplexity)那样统一的优化指标。一个在实验室跑分满分的模型,如果处理不了真实仓库里的光影变化,那就是废物。
3. 飞轮是由那些无聊的琐事构成的
这引出了整个架构中最被低估的部分:部署基础设施。这不只是销售问题,而是极其枯燥、毫无光环的工程开发,旨在将一次性的部署转化为可复用、可累积的资产。它是远程诊断、数据路由和可靠更新的工具链。
如果没有这个“飞轮”,整个系统就会锁死。机器人进不了真实环境,模型就拿不到进化所需的真实数据。无论你投入多少算力,能力曲线都会变平。York 认为,泡沫就存在于“那些已经理解这一点的团队,与那些仍在为跑分数据和演示视频进行优化的团队之间的鸿沟中”。
唯一的出路是“死磕”到底
面对这一现实,领域内已经分成了两派。一派是模型优先,赌只要“大脑”足够强大,硬件就会变成廉价的通用商品。另一派是硬件优先,认为完美的身体才是关键,开源软件会填补剩下的空白。
York 和 Dyna 坚定地站在第三个阵营:垂直整合。他们选择这条路不是因为时髦,而是因为在部署其 DYNA-1 模型的一年里,他们发现除此之外别无他法。他们通过惨痛的教训明白,部署不会奇迹般地变简单。反馈闭环必须同时在研究、硬件和部署端完成闭合。
这就是接下来的工作。这不再是追求下一个刷屏的演示视频,而是极其艰辛的过程:构建一个能让第十次部署比第一次更快、更可靠的系统。第一支真正破解这个密码的团队将不仅赢得市场,更将定义市场。在那之前,我们都只是在一场极其昂贵的科学博览会中当观众。
