
**구글 딥마인드(Google DeepMind)**가 로봇에게 물리적 세계에 대한 ‘상식’을 이식한 최신 ‘신체화된 추론(Embodied Reasoning)’ 모델, Gemini Robotics-ER 1.6을 공개했습니다. 이번 업데이트는 단순히 입력된 명령을 기계적으로 수행하는 수준을 넘어, 로봇이 주변 환경을 시각적으로 이해하고 상황에 맞춰 스스로 판단하며 상호작용하는 능력을 비약적으로 끌어올렸습니다.
Gemini Robotics-ER 1.6의 핵심 업그레이드 중 하나는 한층 정교해진 시각 및 공간 이해력입니다. 그 정점은 바로 ‘포인팅(pointing)’ 능력에서 드러납니다. 어질러진 작업대 위에서 특정 공구를 찾아달라고 요청하면, 모델은 수많은 잡동사니 사이에서 정확한 아이템을 식별하고 개수를 세며 위치를 짚어냅니다. 이는 단순한 물체 인식을 넘어, 최적의 집기(grasp) 궤적을 설계하거나 “렌치를 공구함으로 옮겨라” 같은 관계형 명령을 수행하기 위한 고차원적 공간 논리의 토대가 됩니다. 심지어 “지정된 상자에 들어갈 만큼 작은 물건들만 골라내"와 같은 제약 조건이 포함된 추론도 가능해졌습니다.
또한, 로봇 공학의 고질적인 난제인 ‘작업 완료 여부 판단’ 문제도 정면으로 돌파했습니다. Gemini Robotics-ER 1.6은 고도화된 멀티뷰 추론(multi-view reasoning)을 통해 천장에 설치된 카메라와 로봇 손목에 달린 카메라 등 여러 위치에서 들어오는 라이브 영상을 실시간으로 합성해 전체 상황을 파악합니다. 덕분에 물체가 시야에서 잠시 가려지더라도 로봇이 당황하여 무한 루프에 빠지거나 작업을 포기하는 상황을 방지할 수 있습니다.
이것이 왜 중요한가?
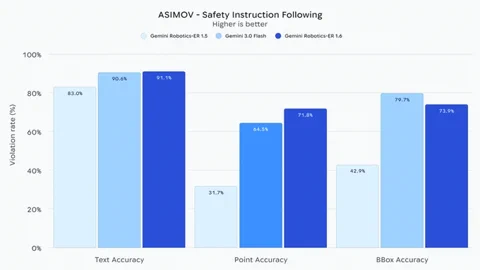
이번 업데이트는 단순한 성능 향상 그 이상을 의미합니다. 진정한 자율 로봇을 구현하기 위한 ‘기초 체력’을 다진 것이기 때문입니다. 아날로그 계기판의 수치를 읽고, 여러 대의 카메라 피드를 통합하며, 복잡한 공간적 관계를 이해하는 능력은 단순한 공장용 로봇 팔과 실전 투입이 가능한 필드 로봇을 가르는 결정적인 차이입니다. 딥마인드는 공식 발표를 통해 이번 모델이 역대 가장 안전한 로봇 모델이라고 강조했습니다.
무엇보다 주목할 점은 물리적 안전 제약을 준수하는 능력이 눈에 띄게 개선되었다는 것입니다. 액체를 피해서 이동하거나 20kg이 넘는 물건은 들지 않는 등의 지침을 정확히 이해합니다. 보고에 따르면, 기존 Gemini 3.0 Flash 모델과 비교했을 때 영상 속에서 인간의 부상 위험을 감지하는 능력이 약 10% 더 뛰어납니다. 예측 불가능한 인간의 환경에서 로봇이 안전하고 신뢰할 수 있는 파트너로 거듭나기 위한 중요한 진전입니다. 현재 이 모델은 Gemini API와 Google AI Studio를 통해 개발자들에게 제공되고 있습니다.
