
스마트폰 카메라가 그저 흐릿한 콘서트 사진이나 찍는 도구라고 생각했다면 오산입니다. 연구진들이 이제 이 렌즈를 실시간 3D 스캐너로 탈바꿈시켰기 때문입니다. **앤트그룹(Ant Group)**의 엠보디드 AI 부문인 **로비앤트(Robbyant)**는 최근 단일 스트리밍 영상만으로 정밀하고 거대한 환경을 재구성하는 새로운 3D 파운데이션 모델, **링봇-맵(LingBot-Map)**을 오픈 소스로 공개했습니다. 여기서 압권은 초당 20프레임(FPS)이라는 쾌속 성능입니다. 기존의 사진측량(Photogrammetry) 방식들이 마치 거북이걸음을 하는 것처럼 보일 정도로 압도적인 속도입니다.
이 기술의 핵심 비결은 **기하학적 컨텍스트 트랜스포머(Geometric Context Transformer, GCT)**라는 혁신적인 구조에 있습니다. 이는 단순히 시각적 문제에 트랜스포머 모델을 덧붙인 수준이 아닙니다. GCT는 단안(monocular) SLAM 시스템의 고질적인 약점인 ‘드리프트(오차 누적)’ 현상을 해결하기 위해 정교하게 설계되었습니다. 세 가지 병렬 어텐션 메커니즘—안정적인 좌표 고정을 위한 앵커 컨텍스트, 미세한 디테일을 위한 로컬 포즈 참조 윈도우, 그리고 장거리 오차를 보정하는 궤적 메모리—을 교묘하게 활용해 기하학적 정보를 관리합니다. 덕분에 링봇-맵은 10,000프레임이 넘는 시퀀스에서도 “정확도 변화가 거의 없는” 처리가 가능하다는 것이 로비앤트 측의 설명입니다. 해당 프로젝트는 현재 GitHub에서 확인할 수 있습니다. 하이퍼링크: Robbyant/lingbot-map
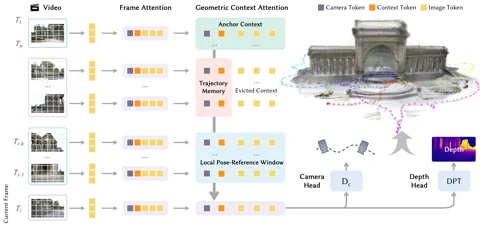
성능 수치는 그야말로 대담하다 못해 파격적입니다. 까다롭기로 유명한 옥스퍼드 스파이어스(Oxford Spires) 데이터셋에서 링봇-맵은 절대 궤적 오차(Absolute Trajectory Error)를 단 6.42미터로 줄이며, 기존의 최고 수준 스트리밍 방식보다 2.8배나 향상된 성능을 보여주었습니다. 심지어 모든 이미지를 한꺼번에 처리할 수 있는 오프라인 방식들보다도 뛰어난 성적을 거뒀습니다. ETH3D 벤치마크에서는 F1 스코어 98.98을 기록하며 2위 그룹을 21%포인트 이상의 격차로 따돌리고 압도적인 1위를 차지했습니다. 기술적 디테일에 목마른 독자라면 arXiv에 게재된 논문을 통해 전체 방법론을 살펴볼 수 있습니다. 하이퍼링크: Read the paper on arXiv
이것이 왜 중요한가?
링봇-맵은 ‘공간 지능의 대중화’를 향한 중대한 진전입니다. 값비싼 라이다(LiDAR) 센서나 복잡한 멀티 카메라 리그 없이도 로보틱스, 자율주행차, 증강 현실(AR) 분야에서 저비용·고성능 3D 인지 기능을 구현할 수 있는 길을 열었기 때문입니다. 단순히 보기 좋은 포인트 클라우드를 만드는 것이 목적이 아닙니다. 기계에게 물리적 세계에 대한 연속적이고 실시간적인 이해력을 부여하는 것이 핵심입니다. 하나의 ‘3D 파운데이션 모델’로서, 이는 텍스트나 이미지를 처리하는 수준을 넘어 복잡하고 비정형화된 환경을 지각하고 탐색하며 상호작용하는 AI를 구축하려는 거대한 흐름의 일부입니다. 이는 곧 우리가 마주할 엠보디드 AI 시대의 초석이 될 것입니다.
