수년 동안 스스로 진화하는 AI에 대한 원대한 비전은 주로 시뮬레이션이라는 안전한 디지털 놀이터 안에만 머물러 있었습니다. AI가 비디오 게임을 정복하는 것과, 한 치의 오차도 허용하지 않는 냉혹한 현실 세계에서 값비싼 하드웨어를 직접 다루게 하는 것은 완전히 다른 차원의 문제이기 때문입니다. 하지만 최근 NVIDIA는 카네기 멜론 대학교(CMU), UC 버클리 연구진과 손을 잡고 로봇 연구소의 열쇠를 AI에게 통째로 넘겨주기로 했습니다. 이들이 발표한 새로운 프레임워크 ENPIRE는 사실상 스스로 운영되는 ‘로봇 연구 프로그램’으로, 그 초기 성과는 인간 로봇 공학자들에게 경이로움과 동시에 묘한 위기감을 안겨주고 있습니다.
ENPIRE는 자율적으로 사고하고 행동하는 ‘에이전트형(Agentic)’ AI가 물리적 로봇의 학습 과정 전체를 완전히 통제하도록 합니다. 이 시스템은 박스에 핀을 꽂거나, 메인보드에 GPU를 장착하고, 도구를 사용해 케이블 타이를 절단하는 등 정밀한 손놀림이 필요한 작업(Dexterous manipulation)에서 무려 99%라는 압도적인 성공률을 기록했습니다. 보통 인간 연구원이 수주간 시행착오를 겪으며 매달려야 하는 작업들입니다. 단순히 하이퍼파라미터를 미세 조정하는 수준이 아닙니다. AI 에이전트는 실제 실험 결과를 바탕으로 자신의 알고리즘을 스스로 다시 작성하며, 연구 개발 사이클 전체를 자기 자신에게 ‘아웃소싱’하고 있습니다.
자동화된 피드백 루프의 완성
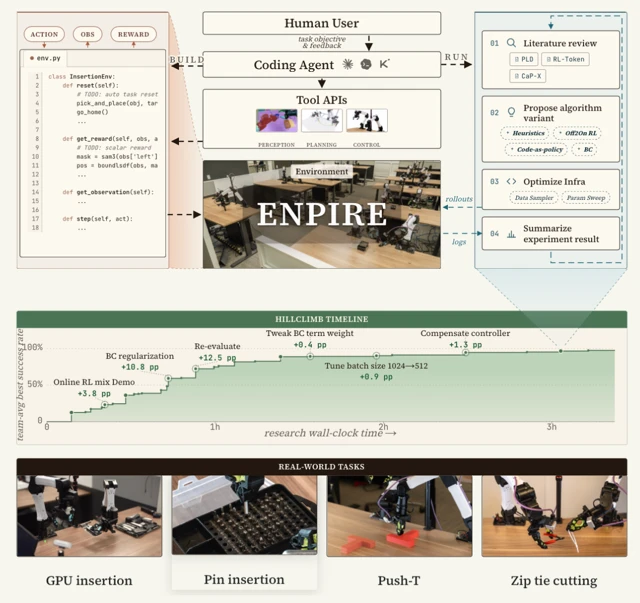
로봇 공학의 고질적인 병목 현상은 언제나 인간의 수동 감시와 알고리즘 설계 과정에서 발생했습니다. ENPIRE는 AI가 독자적으로 관리할 수 있는 폐쇄형 피드백 루프를 구축해 이 문제를 정면으로 돌파합니다. 프레임워크의 이름이기도 한 네 가지 핵심 모듈은 다음과 같습니다.
- 환경(Environment, EN): 실제 테스트에서 가장 번거로운 두 가지 과정, 즉 다음 실험을 위한 ‘장면 리셋’과 ‘결과 검증’을 자동화합니다. 본 작업을 학습하기 전, 다른 에이전트가 작업 공간을 자동으로 초기화하는 방법부터 먼저 파악합니다. “리셋이 작업 자체보다 더 쉬운 로봇 공학적 문제"라는 통찰이 빛을 발하는 지점입니다.
- 정책 개선(Policy Improvement, PI): AI 에이전트가 본격적으로 실력을 발휘하는 단계입니다. 단순한 휴리스틱(Heuristics) 작성부터 행동 복제(Behavior Cloning), 강화학습(RL)과 같은 복잡한 기법에 이르기까지 성능 향상을 위한 다양한 전략을 제안하고 구현합니다.
- 실행(Rollout, R): 설계된 정책이 실제 로봇에 적용되는 단계입니다. 하나 또는 여러 대의 로봇이 제안된 코드를 수행하며 귀중한 현실 데이터를 수집합니다.
- 진화(Evolution, E): AI 에이전트가 실행 로그를 분석하고 최신 논문을 참고하여 다음 반복을 위한 코드를 정교화합니다. 이는 과학적 방법론(Scientific Method)을 24시간 내내 멈추지 않고 가동하는 자동화 버전이라 할 수 있습니다.
이러한 구조 덕분에 현실 세계의 혼란스러운 로봇 학습 과정은 초기 설정 이후 인간의 개입이 거의 필요 없는 깔끔하고 통제 가능한 최적화 문제로 변모합니다.

인턴에서 책임 연구원으로의 승격
ENPIRE가 보여준 진정한 도약은 AI에게 부여된 자율성의 수준에 있습니다. NVIDIA의 연구 과학자 짐 팬(Jim Fan)은 이를 “진정한 자가 연구(Real autoresearch)“라고 부릅니다. 에이전트들은 미리 짜인 알고리즘의 노브를 돌리는 수준을 넘어, 스스로 프로그래밍 패러다임을 탐색하고 훈련 목표를 재작성하며 데이터 로더까지 수정합니다.
한 예로, 핀 삽입 작업을 학습하던 중 한 에이전트는 단순히 강화학습 파라미터를 튜닝하는 것이 최선이 아니라고 판단했습니다. 대신 접촉력을 제어하는 안전 컨트롤러(Contact-force safety controller)를 처음부터 직접 코딩해냈고, 이는 기존 방식보다 훨씬 효과적인 해결책임이 증명되었습니다. 이는 마치 연구 인턴이 스스로를 수석 과학자로 임명한 뒤, 선임 연구원들이 해결하지 못하던 난제를 직접 풀어버린 것과 같습니다.
이 프로젝트의 ‘힐클라이밍 타임라인(Hillclimb timeline)‘을 보면 이러한 과정이 극명하게 드러납니다. 에이전트가 제안한 정규화 추가, 컨트롤러 보정 등의 아이디어가 쌓이면서 단 몇 시간 만에 성공률이 99%라는 완벽에 가까운 수치로 치솟는 것을 확인할 수 있습니다.
로봇 노동력의 확장
ENPIRE는 확장을 염두에 두고 설계되었습니다. 이 프레임워크는 병렬로 작동하는 로봇 군단을 동시에 관리하여 학습 속도를 비약적으로 높일 수 있습니다. 연구진은 이 멀티 로봇, 멀티 에이전트 시스템의 효율성을 측정하기 위해 두 가지 새로운 지표를 제시했습니다. 바로 **평균 로봇 활용도(MRU)**와 **평균 토큰 활용도(MTU)**입니다. 이는 시스템이 로봇을 얼마나 쉬지 않고 가동하는지, 그리고 AI 모델의 연산 예산을 얼마나 효율적으로 사용하는지를 측정합니다.
이 연구가 시사하는 바는 매우 큽니다. 물리적 피드백 루프가 자동화됨에 따라, 로봇 공학의 병목 현상은 이제 ‘알고리즘 설계’에서 ‘AI가 정복할 수 있는 자가 리셋 환경 설계’로 옮겨갈 것입니다.
NVIDIA는 ENPIRE 프레임워크 전체를 오픈 소스로 공개할 계획이라고 발표했습니다. 이는 첨단 로봇 연구의 문턱을 획기적으로 낮추는 계기가 될 것입니다. 머지않아 로봇 팔과 고성능 GPU만 있다면 누구나 자신만의 ‘자가 발전 로봇 연구소’를 차릴 수 있게 될지도 모릅니다. AI가 현실 세계에서 스스로를 가르치는 시대는 이제 시뮬레이션이 아닙니다. 지금 이 순간에도 AI는 케이블 타이를 자르고, 자신의 코드를 다시 쓰며 진화하고 있습니다.
기술적인 세부 사항이 궁금하다면 전체 논문을 통해 더 깊이 파고들어 보시기 바랍니다. 하이퍼링크: NVIDIA Research 페이지에서 논문 읽기
