지금 이 순간 로봇 공학계에서 가장 중요한 뉴스가 ‘이족 보행 로봇이 넘어지지 않고 걷는 것’이라고 생각하신다면, 번지수를 잘못 짚으셨습니다. 진짜 지각 변동은 화려한 하드웨어 실험실이 아니라, 아무도 주목하지 않던 ‘데이터 로그’ 속에서 소리 없이 진행 중입니다. Hugging Face 같은 플랫폼을 중심으로 오픈소스 데이터가 기하급수적으로 폭발하며, 로봇 공학의 패러다임이 완전히 뒤바뀌고 있습니다.
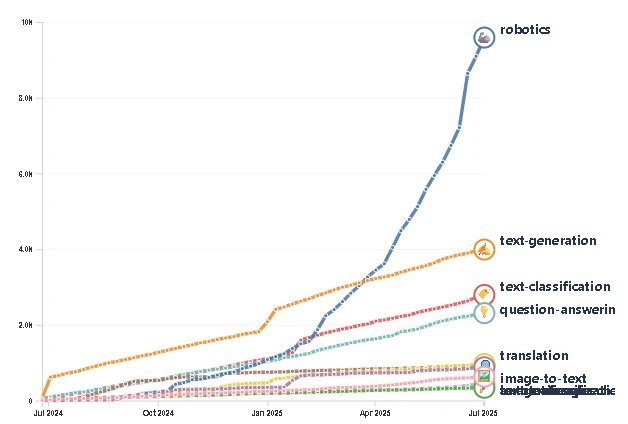
거대언어모델(LLM)이 지난 수년간 공개된 인터넷상의 텍스트를 게걸스럽게 먹어 치우며 성장하는 동안, 로봇들은 쫄쫄 굶고 있었습니다. 로봇은 텍스트로 배우지 않습니다. 비디오 피드, 관절의 움직임, 센서 데이터, 그리고 무엇보다 수많은 ‘실패의 기록’이라는 가공되지 않은 현실 세계의 혼돈으로부터 학습합니다. 과거에 이 귀중한 데이터들은 로봇 기업들이 금고 속에 꽁꽁 숨겨둔 ‘전유물’이었습니다. 하지만 그 시대는 이제 끝났습니다. 지난 1년 사이 Hugging Face에 올라온 로봇 데이터셋은 1,145개에서 약 27,000개로 급증했습니다. 무려 2,400%라는 경이로운 성장률입니다. 불과 3년 전만 해도 전체 카테고리 중 44위에 불과했던 로봇 공학은 이제 텍스트 생성(약 5,000개)을 가볍게 따돌리고 당당히 1위 자리를 꿰찼습니다.
데이터의 대홍수 (The Data Deluge)
이것은 단순히 취미 삼아 올린 프로젝트들의 집합이 아닙니다. 기술 분석가 피에르-알렉상드르 발랑(Pierre-Alexandre Balland)이 제시한 차트를 보면, 공유된 로봇 지식의 ‘캄브리아기 대폭발’이 일어나고 있음을 알 수 있습니다. 특히 이 데이터는 다운로드 횟수 200회 이상의 데이터셋만 필터링한 결과로, 전 세계 수많은 연구자가 이 거대한 저장소를 실제로 활용해 실험하고 모델을 학습시키고 있다는 증거입니다.

이러한 급증은 저렴해진 저장 비용, 개선된 도구, 그리고 AI 업계의 오픈소스 정신이 마침내 하드웨어 영역으로 전이되면서 발생한 ‘퍼펙트 스톰’의 결과입니다. Hugging Face 같은 플랫폼은 공유의 장벽을 획기적으로 낮췄고, 5년 전만 해도 상상할 수 없었던 협업 생태계를 가능하게 했습니다. LeRobot과 같은 프로젝트는 데이터 형식과 도구를 표준화하여 누구나 쉽게 데이터를 기여하고 혜택을 누릴 수 있는 환경을 조성하고 있습니다.
새로운 데이터의 제왕들 (The New Data Barons)
그렇다면 이 거대한 데이터의 댐을 개방하고 있는 주인공은 누구일까요? 흔히 NVIDIA를 GPU 제조사로만 알고 있지만, 이들은 로봇 데이터 분야에서도 압도적인 지배력을 행사하고 있습니다. 2025년 한 해에만 NVIDIA의 오픈 데이터셋 다운로드 횟수는 900만 건을 넘어섰습니다. 특히 범용 로봇 모델인 Isaac GR00T의 사후 학습(post-training)을 위한 데이터셋은 지난 한 해 동안 790만 건의 다운로드를 기록하며 플랫폼 전체에서 독보적인 1위를 차지했습니다. 이는 단순한 자선 사업이 아닙니다. 전체 로봇 생태계의 기초 인프라를 선점하여, 자사의 하드웨어가 생태계의 중심에서 벗어나지 않게 하려는 고도의 전략적 포석입니다.
하지만 NVIDIA만 달리고 있는 것은 아닙니다. 데이터 기여도 상위권은 그야말로 글로벌 AI 강자들의 각축장입니다:
- Shanghai AI Lab이 760만 건이라는 놀라운 수치로 그 뒤를 바짝 쫓고 있습니다.
- Hugging Face 자체 이니셔티브를 통한 데이터도 140만 건에 달합니다.
- 학계의 중심인 **Stanford Vision and Learning Lab (SVL)**은 71만 건 이상의 다운로드를 기록하며 힘을 보태고 있습니다.
- 이 외에도 AgiBot, Yaak AI, AllenAI, 그리고 Unitree Robotics 같은 하드웨어 제조사들까지 이 대열에 합류했습니다.

이것이 ‘진짜’ 혁명인 이유
수십 년 동안 로봇 공학의 발전은 ‘바퀴를 새로 발명해야 하는’ 가혹한 현실에 가로막혀 있었습니다. 컵 하나를 집어 올리는 로봇을 만들려 해도 박사급 인력과 커스텀 로봇, 그리고 수천 시간의 고통스러운 데이터 수집 작업이 필요했습니다. 그렇게 만든 결과물조차 컵의 위치를 왼쪽으로 5cm만 옮기면 고장 나버리는, 특정 작업에만 국한된 나약한 기계에 불과했습니다.
하지만 이번에 불어닥친 오픈 데이터 패러다임은 그 병목 현상을 단숨에 깨부수고 있습니다.
- 진입 장벽의 붕괴: 이제 참신한 학습 알고리즘을 가진 스타트업은 수십억 원대의 하드웨어 장비 없이도 사업을 시작할 수 있습니다. 수십 종류의 로봇과 환경에서 수집된 테라바이트급 실전 데이터를 다운로드해 모델을 학습시키고 검증하면 되기 때문입니다.
- 벤치마킹의 가속화: 공유 데이터셋 덕분에 이제 업계 전체가 동일한 기준에서 서로의 기술력을 겨룰 수 있게 되었습니다. 이는 겉만 번지르르한 기술을 걸러내고, 복잡하고 무질서한 현실 세계에서도 잘 작동하는 진짜 알고리즘을 가려내는 리트머스 시험지가 될 것입니다.
- 플라이휠 효과(Flywheel Effect): 고품질 데이터가 많아질수록 더 뛰어난 파운데이션 모델이 탄생합니다. 더 나은 모델은 더 정교한 애플리케이션을 가능케 하고, 이는 다시 더 방대하고 가치 있는 데이터를 생성합니다. 이 선순환 구조야말로 로봇을 연구실 밖으로 끌어내 우리 일상으로 데려다줄 핵심 엔진입니다.
미래의 로봇 공학은 단순히 매끄러운 하드웨어를 가진 회사가 아니라, 가장 풍부하고 다양한 데이터를 보유한 생태계에 의해 정의될 것입니다. 춤추는 휴머노이드 영상이 대중의 눈을 즐겁게 할지는 몰라도, 로봇 시대의 진짜 인프라는 지금 이 순간에도 데이터셋 하나하나를 통해 조용히, 그리고 거침없이 구축되고 있습니다. 소프트웨어 세상을 뒤바꿨던 오픈소스 혁명이 이제 물리 세계의 문을 두드리고 있습니다.