
Google DeepMindが、ロボットに物理世界での「常識」をインストールするための最新アップデート、Gemini Robotics-ER 1.6を発表しました。この「Embodied Reasoning(具現化された推論)」モデルは、ロボットが単にプログラムされた動作を繰り返す段階を脱し、周囲の環境を「見て、理解し、論理的に判断して動く」能力を飛躍的に向上させています。
Gemini Robotics-ER 1.6の目玉となる進化は、視覚および空間認識能力の強化です。その真価は、新たに追加された「ポインティング(指し示し)」機能によく現れています。例えば、道具が散乱したワークショップで特定の工具を探すよう指示すると、モデルは無関係な物体を無視しながら、目的のアイテムを正確に特定し、カウントし、ピンポイントで指し示すことができます。これは単なる物体検出ではありません。完璧なグリップのための軌道計算や、「レンチを工具箱に移動して」といった相対的なコマンドの理解など、より複雑な空間ロジックを構築するための基礎となるものです。また、「指定した容器に入るサイズのオブジェクトをすべて選ぶ」といった、物理的な制約を伴う推論も可能になっています。
さらに、このモデルはロボット工学における長年の難題である「タスクが本当に完了したかどうかを判断する」という課題にも踏み込んでいます。高度な「マルチビュー・リーズニング(多視点推論)」により、Gemini Robotics-ER 1.6は、例えば頭上の俯瞰カメラとロボットの腕に装着されたカメラなど、複数のライブ映像を統合して現場の完全な状況を把握します。これにより、物体が一時的に死角に入っただけでロボットが混乱してループに陥ったり、タスクを失敗したりするリスクを回避できるようになりました。
なぜこれが重要なのか?
今回のアップデートは、単なる性能の微増ではありません。これはロボットの「自律性」を支える基礎体力を底上げするものです。アナログの計器を読み取り、複数のカメラフィードを融合させ、複雑な空間関係を理解する能力こそが、単なる「工場の作業アーム」と、現場で役立つ「フィールドロボット」を分かつ境界線となります。DeepMindの公式発表によれば、これは同社史上「最も安全な」ロボットモデルであるとされています。
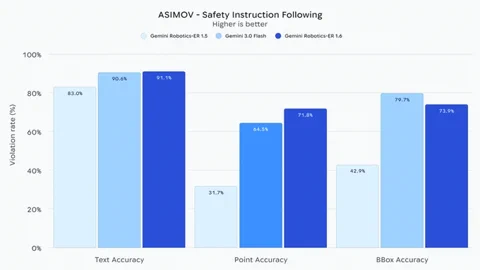
特筆すべきは、Gemini Robotics-ER 1.6が物理的な安全制約を遵守する能力を「大幅に向上」させている点です。「液体を避ける」「20kg以上のものは持ち上げない」といった指示を正確に理解します。ベースモデルであるGemini 3.0 Flashと比較して、映像内での人間の負傷リスクを察知する能力は10%向上したと報告されています。こうした安全性と現実世界での推論能力へのフォーカスは、予測不能な人間社会の環境でロボットが信頼に足るパートナーとして機能するための決定的な一歩と言えるでしょう。このモデルはすでに、Gemini APIおよびGoogle AI Studioを通じてデベロッパー向けに公開されています。
