
スマホのカメラ。これまで、ライブ会場でボケボケの写真を撮るのが関の山だと思っていたなら、その認識は今日で過去のものになる。研究者たちは今、そのレンズを「リアルタイム3Dスキャナー」へと変貌させようとしている。
Ant Groupの具現化AI(Embodied AI)部門であるRobbyantは、動画ストリーミングから詳細かつ大規模な環境を再構築する新しい3D基盤モデル「LingBot-Map」をオープンソース化した。驚くべきは、秒間20フレーム(20 FPS)という爆速での処理だ。従来のフォトグラメトリ(写真測量)手法が、まるで泥沼の中を歩いているかのように思えるほどのスピードである。
その核心にあるのは、「Geometric Context Transformer(GCT)」という独自のアーキテクチャだ。これは単に既存のTransformerを視覚問題に流用したものではない。単眼カメラ(モノキュラー)によるSLAM(自己位置推定と環境地図作成)の最大の弱点、すなわち「ドリフト(累積誤差によるズレ)」を克服するためにゼロから設計されている。GCTは、3つの並列アテンション機構——安定した座標の接地を実現する「アンカー・コンテキスト」、微細なディテールを捉える「ローカル・ポーズ参照ウィンドウ」、そして長距離の誤差を修正する「軌跡メモリ」——を巧みに操る。これにより、LingBot-Mapは1万フレームを超えるシーケンスでも、Robbyantが「ほぼ精度を落とさない」と豪語するレベルでの処理を可能にした。プロジェクトは現在、GitHubで公開されている。
ハイパーリンク:Robbyant/lingbot-map
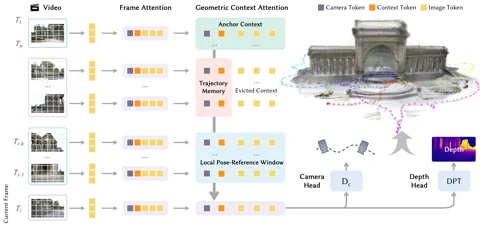
発表されたパフォーマンスの数値は、控えめに言っても「破格」だ。難易度の高いOxford Spiresデータセットにおいて、LingBot-Mapは絶対軌跡誤差(ATE)わずか6.42メートルを記録。これは、従来の最高水準のストリーミング手法を2.8倍も上回る改善だ。さらに、すべての画像を一度にじっくり処理できるオフライン手法さえも凌駕しているというから驚きだ。ETH3DベンチマークではF1スコア98.98を叩き出し、2位に21ポイント以上の大差をつけて圧勝した。技術的な詳細に飢えている読者は、arXivで公開されている論文をチェックしてほしい。
ハイパーリンク:Read the paper on arXiv
なぜこれが重要なのか?
LingBot-Mapは、「空間知能の民主化」に向けた巨大な一歩を意味している。高価なLiDARや複雑なマルチカメラ・システムを必要とせず、安価な単眼カメラだけで高性能な3D認識が可能になれば、ロボティクス、自動運転、そして拡張現実(AR)の扉は一気に開かれるだろう。
これは単に「綺麗な点群データ」を作ることではない。マシンが物理世界をリアルタイムかつ継続的に「理解」できるようにすることなのだ。「3D基盤モデル」として登場したこの技術は、AIがテキストや画像といったデジタルデータを超え、構造化されていない複雑な現実世界を認識し、ナビゲートし、相互作用するための礎となる。これこそが、具現化AI(Embodied AI)が真に社会に溶け込むためのミッシングピースなのかもしれない。
