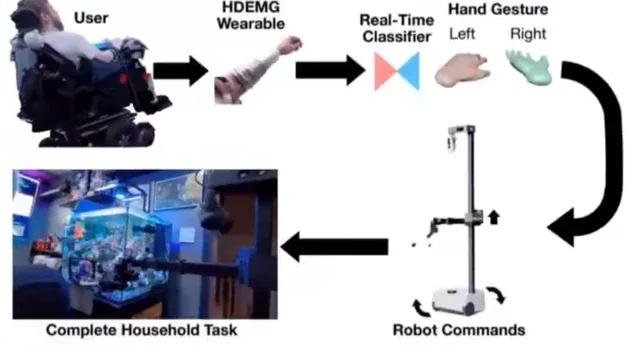
カーネギーメロン大学とNVIDIAの研究者たちは、どうやらロボットもインターン生と同じく、自分のへまから学ぶべきだと判断したようだ。彼らが導入した新たなフレームワーク「PLD」(Probe, Learn, Distill)は、Vision-Language-Action(VLA)モデルが高精度なタスクにおいて自律的に改善することを可能にする。これは、人間のデモンストレーションを模倣させるという、マイクロチップを手彫りするのと同レベルの非効率性で、拡張性など夢のまた夢だった従来の骨の折れるロボット教育手法から大きく脱却するものだ。
PLDメソッドは、失敗を強みに変えるべく設計された3段階のプロセスだ。まず、ロボットは既存の知識でタスクを試みることで、自身の限界を探る(probe)。そして、必然的にしくじる(例えば、提供するはずだった飲み物をこぼしてしまうなど)と、残差強化学習によって訓練された軽量な「レスキューポリシー」が介入し、行動を修正する。最後に、システムはこの成功した回復を蒸留(distill)し、新しいデータでメインモデルを微調整するのだ。本質的に、ロボットは失敗するたびに少しずつ賢くなり、手取り足取り教える必要は一切ない。このシステムは既にLIBEROベンチマークで99%の成功率を、そして特定の実世界操作タスクでは100%の成功率を実証している。
なぜこれが重要なのか?
これは、真に適応性の高いロボットを生み出すための画期的な一歩だ。あらゆる想定される状況に対応する完璧な動きのライブラリでプログラムされるのではなく、PLDを搭載したロボットは、斬新で不完全な経験から独自の訓練データを生成できる。この自己改善ループは、開発時間とコストを劇的に削減し、あなたの散らかり放題のキッチン¹のような複雑で非構造化された環境でも、ロボットがより実用的になる可能性を秘めている。「見て学ぶ」から「実践して学ぶ」へ、そしてさらに重要なことに、「危うくやらかしそうになったところから学ぶ」へと、パラダイムが転換するのだ。
¹ 訳注:もちろん、あなたのキッチンが散らかっているとは限りません。あくまで比喩です。しかし、もしそうなら、このロボットは救世主かもしれません。