Per anni, la grande visione di un’intelligenza artificiale capace di migliorarsi da sola è rimasta confinata quasi esclusivamente nei “recinti” digitali delle simulazioni. Un conto è vedere un’IA che domina un videogioco; un altro, decisamente più complesso, è permetterle di armeggiare con hardware costoso nel caos imprevedibile del mondo reale. Ora, i ricercatori di NVIDIA, in collaborazione con la Carnegie Mellon University e la UC Berkeley, hanno deciso di consegnare letteralmente le chiavi del laboratorio all’algoritmo. Il loro nuovo framework, ENPIRE, crea essenzialmente un programma di ricerca robotica che gira in totale autonomia, e i primi risultati sono tanto impressionanti quanto, per certi versi, disarmanti per gli ingegneri robotici umani.
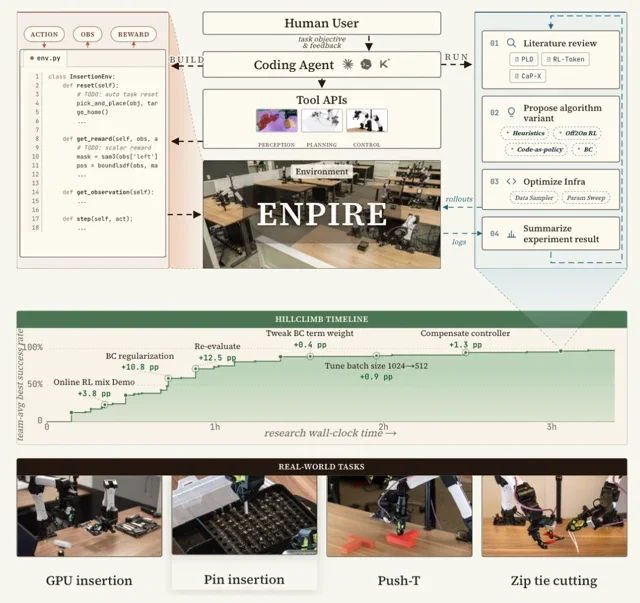
ENPIRE permette a un’IA “agentica” — ovvero agenti di codifica in grado di ragionare e agire autonomamente — di assumere il pieno controllo del processo di apprendimento fisico. Il sistema ha raggiunto un incredibile tasso di successo del 99% in compiti di manipolazione fine che normalmente richiederebbero settimane di tentativi ed errori guidati dall’uomo: dall’inserimento di pin in una scatola all’alloggiamento di una GPU, fino al taglio di una fascetta serracavi con un attrezzo. Non si tratta solo di calibrare qualche iperparametro; gli agenti IA stanno riscrivendo i propri algoritmi basandosi sui risultati ottenuti sul campo, esternalizzando di fatto l’intero ciclo di ricerca e sviluppo a se stessi.
Il loop di feedback automatizzato
Il vero collo di bottiglia nella robotica è sempre stato il laborioso processo di supervisione umana e ingegneria algoritmica. ENPIRE affronta il problema di petto creando un loop di feedback chiuso e ripetibile che un’IA può gestire interamente da sola. Il framework è suddiviso in quattro moduli intelligenti che formano il suo acronimo:
- Environment (EN - Ambiente): Questo modulo automatizza le due parti più tediose dei test nel mondo reale: il ripristino della scena per il tentativo successivo e la verifica del risultato. Prima ancora che l’IA inizi a imparare il compito principale, un altro agente capisce come resettare automaticamente lo spazio di lavoro — un’intuizione chiave, dato che il reset è spesso un problema robotico più semplice del compito stesso.
- Policy Improvement (PI - Miglioramento della Policy): Qui gli agenti IA entrano in azione. Possono proporre e implementare una vasta gamma di strategie per migliorare, dalla scrittura di semplici euristiche all’impiego di metodi complessi come il behavior cloning o l’apprendimento per rinforzo (Reinforcement Learning - RL).
- Rollout (R - Esecuzione): È il momento in cui il metallo incontra la realtà. Il modulo esegue la strategia proposta dall’agente su uno o più robot fisici, raccogliendo preziosi dati dal mondo reale.
- Evolution (E - Evoluzione): Gli agenti IA analizzano i log delle esecuzioni, consultano la letteratura scientifica alla ricerca di nuove idee e poi raffinano il codice per l’iterazione successiva. È una versione implacabile e automatizzata del metodo scientifico, attiva 24 ore su 24, 7 giorni su 7.
Questa struttura trasforma il processo caotico dell’apprendimento robotico reale in un problema di ottimizzazione pulito e controllabile, che richiede un intervento umano minimo dopo la configurazione iniziale.

Da stagista a ricercatore capo
Ciò che rende ENPIRE un salto generazionale è il livello di autonomia concesso all’IA. È quello che il ricercatore di NVIDIA Jim Fan definisce “vera autoresearch”. Gli agenti non si limitano a ruotare le manopole di un algoritmo pre-scritto; esplorano attivamente diversi paradigmi di programmazione, riscrivono i propri obiettivi di addestramento e modificano persino i caricatori di dati (data loaders).
In un caso specifico, mentre imparava a inserire un pin, un agente ha deciso autonomamente che ottimizzare i parametri del Reinforcement Learning non fosse la strada migliore. Ha invece scritto da zero il proprio controller di sicurezza basato sulla forza di contatto, che si è rivelato una soluzione molto più efficace. È l’equivalente IA di uno stagista che si promuove a scienziato capo e risolve un problema su cui lo staff senior si era arenato.
La “hillclimb timeline” del progetto visualizza magnificamente questo processo, mostrando come le diverse idee proposte dagli agenti — come l’aggiunta di regolarizzazione o la compensazione del controller — spingano incrementalmente il tasso di successo verso quel quasi perfetto 99% in poche ore.
Scalare la forza lavoro robotica
ENPIRE è progettato per scalare. Il framework può gestire un’intera flotta di robot che operano in parallelo, accelerando drasticamente il processo di apprendimento. Per quantificare l’efficienza di questo sistema multi-robot e multi-agente, i ricercatori hanno proposto due nuove metriche: Mean Robot Utilization (MRU) e Mean Token Utilization (MTU). Queste misurano quanto efficacemente il sistema tenga occupati i robot e quanto efficientemente utilizzi il budget computazionale del modello IA.
La promessa di questa ricerca è profonda. Automatizzando il loop di feedback fisico, il collo di bottiglia nella robotica potrebbe spostarsi dalla faticosa progettazione di algoritmi alla creazione di ambienti autosufficienti e capaci di resettarsi da soli, che gli agenti IA potranno poi “conquistare” in autonomia.
NVIDIA ha annunciato l’intenzione di rendere l’intero framework ENPIRE open-source, il che potrebbe democratizzare l’accesso alla ricerca robotica avanzata. Presto, chiunque disponga di un braccio robotico e di una GPU di buon livello potrebbe essere in grado di allestire il proprio laboratorio di robotica che si auto-migliora a casa. L’era dell’IA che impara da sola nel mondo reale non è più una simulazione: è già qui, taglia fascette e riscrive il proprio codice per finire il lavoro.
Per approfondire i dettagli tecnici, è possibile consultare il paper completo. Link: Leggi il paper sulla pagina di NVIDIA Research.