
Amikor már épp elkönyveltük volna, hogy a mobilunk kamerája legfeljebb arra jó, hogy értékelhetetlenül homályos fotókat készítsünk a kedvenc zenekarunkról a fesztiválokon, a kutatók fogták magukat, és egy valós idejű 3D-szkennert varázsoltak belőle. Az Ant Group robotikai szárnya, a Robbyant nemrég tette nyílt forráskódúvá a LingBot-Map nevű új, 3D alapmodelljét, amely egyetlen élő videófolyamból képes részletes, nagy kiterjedésű környezetek rekonstrukciójára. A poén? Mindezt stabil 20 képkocka/másodperces sebességgel teszi – ez olyan tempó, ami mellett a hagyományos fotogrammetriai eljárások úgy festenek, mintha sűrű szirupban próbálnának sprintelni.
A recept lelke egy újszerű architektúra, a Geometric Context Transformer (GCT). Ez nem csak egy sokadik transformer, amit ráerőszakoltak egy látásalapú problémára. A GCT-t kifejezetten arra tervezték, hogy kiiktassa a monokuláris (egykamerás) SLAM-rendszerek Achilles-sarkát: a driftet, vagyis a pozicionálási elcsúszást. A rendszer zsenialitása három párhuzamos figyelem-mechanizmusban rejlik: egy horgony-kontextus a stabil koordinátákért, egy lokális póz-referencia ablak a finom részletekért, és egy trajektória-memória, amely a nagy távolságokon felhalmozódó hibákat korrigálja. Ennek köszönhetően a LingBot-Map akár 10 000 képkockánál hosszabb sorozatokat is képes feldolgozni anélkül, hogy a pontossága csorbát szenvedne. A projekt már elérhető a GitHubon. Link: Robbyant/lingbot-map
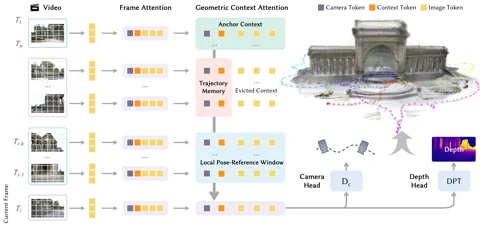
A teljesítményre vonatkozó ígéretek – finoman szólva is – arcpirítóan merészek. A kőkemény Oxford Spires adatsoron a LingBot-Map mindössze 6,42 méteres abszolút trajektória-hibát produkált, ami közel 2,8-szoros javulás a korábbi legjobb streaming módszerekhez képest. Sőt, még azokat az offline eljárásokat is lepipálja, amelyeknek megadatik az a luxus, hogy az összes képet egyszerre, utólag dolgozzák fel. Az ETH3D benchmarkon 98,98-as F1-pontszámot ért el, amivel több mint 21 százalékpontot vert rá a második helyezettre. Aki imád elmerülni a véresen komoly technikai részletek bugyraiban, az a teljes módszertant megtalálja az arXiv-en publikált tanulmányban. Link: Olvasd el a tanulmányt az arXiv-en
Miért fontos ez?
A LingBot-Map egy hatalmas lépés a térbeli intelligencia demokratizálása felé. Azzal, hogy nincs szükség méregdrága LiDAR-szenzorokra vagy bonyolult többkamerás rendszerekre, megnyílik az út az olcsó, de bivalyerős 3D érzékelés előtt a robotikában, az önvezető járművekben és a kiterjesztett valóságban. Itt már nem csak látványos pontfelhőkről van szó; ez arról szól, hogy a gépek folyamatos, valós idejű képet kapjanak a fizikai világról. Mint „3D alapmodell”, ez a fejlesztés egy nagyobb trend része: olyan MI-t építünk, amely nemcsak szöveget vagy képeket dolgoz fel, hanem érzékeli, navigálja és interakcióba lép a komplex, strukturálatlan környezettel – ez pedig a testet öltött mesterséges intelligencia (embodied AI) jövőjének alapköve.
