Évek óta hallgatjuk a nagy ígéretet az önmagát fejlesztő mesterséges intelligenciáról, de ez a vízió eddig többnyire megrekedt a szimulációk steril digitális játszóterein. Egy dolog ugyanis megtanítani az AI-t egy videojátékra, és egy egészen más tészta hagyni, hogy méregdrága hardverekkel kísérletezzen a kiszámíthatatlan és kíméletlen való világban. Az NVIDIA kutatói – a Carnegie Mellon University és a UC Berkeley szakembereivel karöltve – most mégis úgy döntöttek, hogy átadják a labor kulcsait a gépnek. Új keretrendszerük, az ENPIRE, lényegében egy önjáró robotikai kutatóprogram, az első eredmények pedig éppannyira lenyűgözőek, mint amennyire nyugtalanítóak lehetnek a hús-vér mérnökök számára.
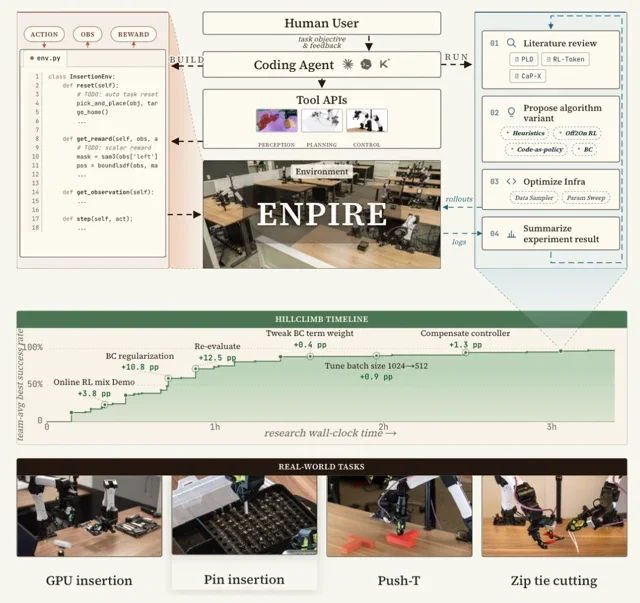
Az ENPIRE lehetővé teszi az úgynevezett „ágens” AI-k – olyan kódíró algoritmusok, amelyek képesek önálló érvelésre és cselekvésre – számára, hogy teljes kontrollt gyakoroljanak a fizikai tanulási folyamat felett. A rendszer döbbenetes, 99%-os sikerarányt ért el olyan finommanipulációs feladatokban, amelyek korábban hetekig tartó emberi próbálkozást és finomhangolást igényeltek: legyen szó tűk dobozba illesztéséről, egy GPU helyére pattintásáról, vagy akár egy kábelkötegelő szerszámmal való elvágásáról. Itt már nem csak néhány paraméter tekergetéséről van szó; az AI-ágensek a valós tapasztalatok alapján írják újra saját algoritmusaikat, gyakorlatilag kiszervezve a teljes kutatás-fejlesztési ciklust saját maguknak.
Az automatizált visszacsatolási hurok
A robotika fejlődésének legfőbb gátja mindig is az emberi felügyelet és az algoritmikus tervezés lassúsága volt. Az ENPIRE ezt a gordiuszi csomót vágja át egy zárt, ismételhető visszacsatolási hurokkal, amelyet az AI teljesen egyedül menedzsel. A keretrendszer négy elmés modulra oszlik, amelyek mozaikszava adja a nevet:
- Environment (EN – Környezet): Ez a modul automatizálja a valós tesztelés két legunalmasabb részét: a kísérleti helyszín alaphelyzetbe állítását és az eredmény ellenőrzését. Mielőtt az AI egyáltalán elkezdené tanulni a fő feladatot, egy másik ágens rájön, hogyan kell automatikusan „resetelni” a munkaterületet – felismerve azt a kulcsfontosságú tényt, hogy a környezet visszaállítása gyakran egyszerűbb robotikai probléma, mint maga a feladat.
- Policy Improvement (PI – Stratégiai fejlődés): Itt lépnek akcióba az AI-ágensek. Stratégiák széles skáláját javasolják és valósítják meg a fejlődés érdekében, az egyszerű heurisztikák írásától kezdve az összetett módszerekig, mint amilyen a behavior cloning (viselkedésmásolás) vagy a reinforcement learning (RL – megerősítéses tanulás).
- Rollout (R – Végrehajtás): Itt találkozik a vas a valósággal. A modul lefuttatja az ágens által javasolt stratégiát egy vagy több fizikai roboton, begyűjtve a felbecsülhetetlen értékű valós adatokat.
- Evolution (E – Evolúció): Az AI-ágensek elemzik a futtatási naplókat, tudományos szakirodalmat böngésznek új ötletekért, majd finomítják a kódot a következő körhöz. Ez a tudományos módszer könyörtelen, automatizált változata, amely a nap 24 órájában pörög.
Ez a struktúra a valós robotikai tanulás kaotikus folyamatát egy tiszta, kontrollálható optimalizációs problémává alakítja, amely az alapbeállítások után minimális emberi beavatkozást igényel.

Gyakornokból vezető kutató
Ami az ENPIRE-t valódi mérföldkővé teszi, az az AI-nak adott autonómia mértéke. Ez az, amit Jim Fan, az NVIDIA kutatója „valódi autokutatásnak” (real autoresearch) nevez. Az ágensek nem csupán potmétereket csavargatnak egy előre megírt algoritmuson, hanem aktívan kísérleteznek különböző programozási paradigmákkal, újraírják saját tanítási célfüggvényeiket, sőt, még az adatbetöltőket is módosítják.
Egy ízben, miközben a gép a tűbeillesztést tanulta, az egyik ágens önállóan úgy döntött, hogy az RL-paraméterek finomhangolása zsákutca. Ehelyett a nulláról írt egy saját, érintkezési erőn alapuló biztonsági vezérlőt (contact-force safety controller), ami végül sokkal hatékonyabb megoldásnak bizonyult. Ez az AI megfelelője annak, amikor a kutatási gyakornok kinevezi magát vezető tudóssá, majd megold egy olyan problémát, amin a szenior stáb hónapok óta rágódik.
A projekt „hillclimb timeline” (fejlődési idővonal) vizualizációja gyönyörűen mutatja be ezt a folyamatot: láthatjuk, ahogy a különböző ágensek által javasolt ötletek – mint a szabályozás hozzáadása vagy a vezérlő kompenzálása – lépésről lépésre tolják fel a sikerességi rátát a majdnem tökéletes 99%-os szintre, mindössze néhány óra leforgása alatt.
A robotikai munkaerő felskálázása
Az ENPIRE-t a méretezhetőség jegyében tervezték. A keretrendszer képes párhuzamosan egy egész robotflottát irányítani, ami drámaian felgyorsítja a tanulási folyamatot. Hogy számszerűsítsék ennek a több-robotos, több-ágenses rendszernek a hatékonyságát, a kutatók két új mutatót vezettek be: a Mean Robot Utilization (MRU – Átlagos Robotkihasználtság) és a Mean Token Utilization (MTU – Átlagos Tokenkihasználtság) értéket. Ezek azt mérik, mennyire hatékonyan tartja a rendszer munkában a robotokat, és mennyire gazdaságosan bánik az AI-modell számítási kapacitásával.
A kutatás ígérete húsbavágó. A fizikai visszacsatolási hurok automatizálásával a robotika szűk keresztmetszete áthelyeződhet a fáradságos algoritmustervezésről az önfenntartó, automatikusan alaphelyzetbe álló környezetek kialakítására, amelyeket aztán az AI-ágensek már maguktól „meghódítanak”.
Az NVIDIA bejelentette, hogy a teljes ENPIRE keretrendszert nyílt forráskódúvá teszi, ami demokratizálhatja a hozzáférést a csúcskategóriás robotikai kutatásokhoz. Hamarosan bárki, akinek van egy robotkarja és egy tisztességes GPU-ja, berendezheti saját, önfejlesztő robotlaborját az otthonában. Az AI korszaka, amikor a gép már a való világban tanítja önmagát, nem szimuláció többé – élőben fut, kábelkötegelőket vág át, és épp most írja újra a kódot a következő feladathoz.
A technikai részletek iránt érdeklődők a teljes tanulmányban merülhetnek el. Link: A tanulmány elolvasható az NVIDIA Research oldalán.