Google DeepMind ने Gemini Robotics-ER 1.6 पेश किया है, जो इनके “Embodied Reasoning” मॉडल का सबसे नया और एडवांस अवतार है। इसका मकसद रोबोट्स को वो ‘कॉमन सेंस’ देना है जिसकी उन्हें भौतिक दुनिया में काम करने के लिए सख्त जरूरत थी। यह नया मॉडल रोबोट की देखने, समझने और अपने आसपास की चीजों के साथ तालमेल बिठाने की क्षमता को एक अलग लेवल पर ले जाता है। अब रोबोट सिर्फ रटी-रटाई कमांड्स फॉलो नहीं करेंगे, बल्कि अपने काम को लेकर बाकायदा तर्क (reasoning) भी करेंगे।
Gemini Robotics-ER 1.6 का एक बड़ा अपग्रेड इसकी विजुअल और स्पेशल (spatial) समझ है, जिसका सबसे शानदार उदाहरण इसकी “पॉइंटिंग” काबिलियत है। अगर आप इसे सामान से भरे किसी बेतरतीब वर्कशॉप में कोई खास औजार ढूंढने को कहें, तो यह मॉडल अब सटीकता से उसे पहचान सकता है, गिन सकता है और फालतू की चीजों को नजरअंदाज कर सही आइटम को पिनपॉइंट कर सकता है। यह सिर्फ चीजें ढूंढने तक सीमित नहीं है; यह एक जटिल ‘स्पेशल लॉजिक’ की बुनियाद है। चाहे वो किसी चीज को परफेक्ट तरीके से पकड़ने के लिए सही रास्ता (trajectory) मैप करना हो या “रिंच को उठाकर टूलबॉक्स में रख दो” जैसे निर्देशों को समझना—यह सब अब इसके लिए आसान है। यहाँ तक कि यह मॉडल यह भी समझ सकता है कि कौन-कौन सी चीजें इतनी छोटी हैं कि एक तय कंटेनर के अंदर समा सकें।
यह मॉडल रोबोटिक्स की उस पुरानी सिरदर्दी को भी सुलझाता है कि रोबोट को यह कैसे पता चले कि काम वाकई पूरा हो गया है। अपनी एडवांस ‘मल्टी-व्यू रीजनिंग’ की बदौलत, Gemini Robotics-ER 1.6 कई कैमरों के लाइव वीडियो स्ट्रीम (जैसे सिर के ऊपर लगा कैमरा और कलाई पर लगा कैमरा) को आपस में जोड़कर पूरे सीन की एक मुकम्मल तस्वीर तैयार कर सकता है। इससे रोबोट किसी काम के बीच में अटकता नहीं है और न ही तब फेल होता है जब कोई चीज किसी दूसरी चीज के पीछे छिप गई हो।
यह क्यों मायने रखता है?
यह अपडेट सिर्फ परफॉरमेंस में मामूली सुधार नहीं है; यह रोबोट्स को पूरी तरह स्वायत्त (autonomous) बनाने की दिशा में एक बड़ी छलांग है। एनालॉग गेज को पढ़ना, कई कैमरा फीड्स को सिंक करना और जटिल स्थानिक संबंधों को समझना ही एक साधारण फैक्ट्री आर्म और एक काम के फील्ड रोबोट के बीच का फर्क है। DeepMind की ऑफिशियल घोषणा के मुताबिक, यह उनका अब तक का सबसे सुरक्षित रोबोटिक्स मॉडल है।
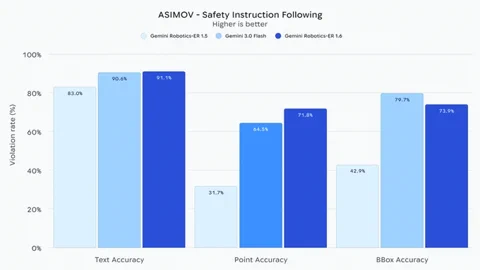
शायद सबसे महत्वपूर्ण बात यह है कि Gemini Robotics-ER 1.6 फिजिकल सेफ्टी के नियमों को मानने में “काफी बेहतर” साबित हुआ है। इसे पता है कि लिक्विड से दूर रहना है या 20 किलो से ज्यादा वजन नहीं उठाना है। बेसलाइन Gemini 3.0 Flash मॉडल की तुलना में, यह वीडियो में इंसानी चोट के जोखिमों को पहचानने में 10% ज्यादा सटीक है। सुरक्षा और रियल-वर्ल्ड रीजनिंग पर यह फोकस उन रोबोट्स के लिए बेहद जरूरी है जो इंसानों के बीच बिना किसी खतरे के काम कर सकें। यह मॉडल अब डेवलपर्स के लिए Gemini API और Google AI Studio पर उपलब्ध है।