अगर आप सोचते हैं कि रोबोटिक्स की दुनिया की सबसे बड़ी खबर किसी दो पैरों वाले रोबोट (bipedal robot) का बिना गिरे चलना है, तो यकीन मानिए, आप गलत दिशा में देख रहे हैं। असली हलचल हार्डवेयर लैब्स में नहीं, बल्कि डेटा लॉग्स (data logs) के भीतर हो रही है। एक ऐसी क्रांति आकार ले रही है जो Hugging Face जैसे प्लेटफॉर्म्स पर सबके सामने है, लेकिन फिर भी मुख्यधारा की नजरों से ओझल है—और इसकी असली ताकत है ओपन-सोर्स डेटा का जबरदस्त विस्फोट।
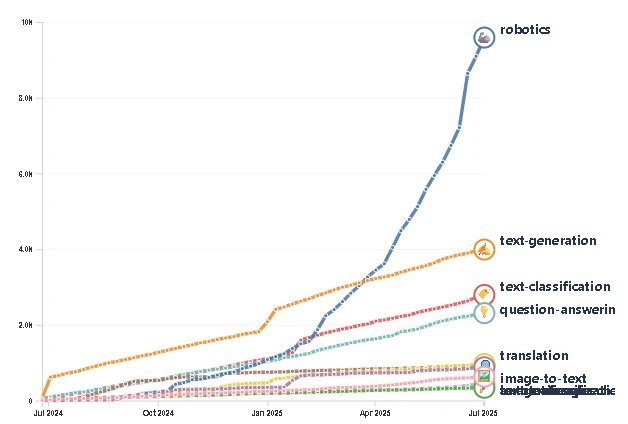
जहाँ एक तरफ ‘लार्ज लैंग्वेज मॉडल्स’ (LLMs) सालों से खुले इंटरनेट के डेटा पर पल रहे हैं, वहीं रोबोट्स अब तक इस मामले में ‘कुपोषित’ ही रहे हैं। रोबोट्स सिर्फ टेक्स्ट से नहीं सीखते; वे भौतिक दुनिया की उलझी हुई और अनिश्चित हकीकत से सीखते हैं—वीडियो फीड, जॉइंट मूवमेंट्स, सेंसर डेटा और सबसे महत्वपूर्ण, अपनी गलतियों से। ऐतिहासिक रूप से, यह कीमती डेटा रोबोटिक्स कंपनियों के लिए किसी ‘कोहिनूर’ से कम नहीं था, जिसे वे अपनी तिजोरियों में बंद रखती थीं। लेकिन अब वह दौर खत्म हो चुका है। पिछले महज एक साल में, Hugging Face पर रोबोटिक्स डेटासेट्स की संख्या 1,145 से उछलकर लगभग 27,000 तक पहुँच गई है। यह 2,400% की ऐसी तूफानी बढ़त है जिसने इस कैटेगरी को सिर्फ तीन साल में 44वें स्थान से सीधे नंबर एक पर पहुँचा दिया है, और 5,000 डेटासेट्स वाले ‘टेक्स्ट जनरेशन’ को बहुत पीछे छोड़ दिया है।
डेटा का सैलाब (The Data Deluge)
यह महज शौकिया प्रोजेक्ट्स का कोई संग्रह नहीं है। टेक एनालिस्ट पियरे-अलेक्जेंड्रे बैलेंड (Pierre-Alexandre Balland) द्वारा साझा किया गया यह चार्ट रोबोटिक ज्ञान के साझा भंडार में आए एक ‘कैम्ब्रियन विस्फोट’ (Cambrian explosion) को दर्शाता है। इस डेटा को केवल उन डेटासेट्स तक सीमित रखा गया है जिन्हें 200 से अधिक बार डाउनलोड किया गया है, जो यह बताता है कि इस विशाल भंडार का उपयोग सक्रिय रूप से प्रयोगों और मॉडल ट्रेनिंग के लिए किया जा रहा है।

यह उछाल एक ‘परफेक्ट स्टॉर्म’ का नतीजा है: सस्ता स्टोरेज, बेहतर टूल्स और AI की दुनिया का ‘ओपन-सोर्स’ मिजाज, जो आखिरकार अब हार्डवेयर की दुनिया में भी अपनी पैठ बना चुका है। Hugging Face जैसे प्लेटफॉर्म्स ने डेटा शेयर करने की बाधाओं को खत्म कर दिया है, जिससे एक ऐसा सहयोगी इकोसिस्टम तैयार हुआ है जो पाँच साल पहले तक अकल्पनीय था। LeRobot जैसी पहल का मकसद फॉर्मेट्स और टूल्स का मानकीकरण करना है, ताकि हर कोई इस साझा ज्ञान में योगदान दे सके और उसका लाभ उठा सके।
डेटा के नए सुल्तान (The New Data Barons)
तो आखिर इस डेटा के सैलाब के द्वार खोल कौन रहा है? वैसे तो आप NVIDIA को उसके पावरफुल GPUs के लिए जानते होंगे, लेकिन यह कंपनी अब रोबोटिक्स डेटा की दुनिया में भी एक महाशक्ति बनकर उभर रही है। अकेले 2025 में, NVIDIA के ओपन डेटासेट्स को 90 लाख से ज्यादा बार डाउनलोड किया गया। उनके Isaac GR00T जनरलिस्ट रोबोट मॉडल की ट्रेनिंग के बाद वाले डेटासेट्स पूरे प्लेटफॉर्म पर सबसे ज्यादा डाउनलोड किए जाने वाले डेटासेट्स हैं, जिन्हें पिछले साल 79 लाख बार डाउनलोड किया गया। यह कोई दान-पुण्य नहीं है; यह पूरे क्षेत्र के लिए एक बुनियादी ढांचा (infrastructure) तैयार करने की एक सोची-समझी रणनीतिक चाल है, ताकि उनका हार्डवेयर इस पूरे इकोसिस्टम के केंद्र में बना रहे।
लेकिन वे अकेले नहीं हैं। डेटा योगदानकर्ताओं की लिस्ट दुनिया के दिग्गज AI पावरहाउसेज से भरी पड़ी है:
- Shanghai AI Lab 76 लाख डाउनलोड्स के साथ कड़ी टक्कर दे रही है।
- Hugging Face खुद अपनी पहलों के जरिए 14 लाख डाउनलोड्स का योगदान दे चुका है।
- Stanford Vision and Learning Lab (SVL) जैसे अकादमिक केंद्रों के डेटासेट्स 7,10,000 से अधिक बार डाउनलोड किए गए हैं।
- अन्य प्रमुख खिलाड़ियों में AgiBot, Yaak AI, AllenAI और यहाँ तक कि Unitree Robotics जैसे हार्डवेयर निर्माता भी शामिल हैं।

यह असली क्रांति क्यों है?
दशकों से, रोबोटिक्स की प्रगति एक कड़वी हकीकत की वजह से थमी हुई थी: हर लैब को ‘पहिए का दोबारा आविष्कार’ करना पड़ता था। एक ऐसा रोबोट बनाने के लिए जो सिर्फ एक कप उठा सके, पीएचडी स्कॉलर्स की एक पूरी टीम, एक कस्टमाइज्ड रोबोट और हजारों घंटों के डेटा कलेक्शन की जरूरत होती थी। नतीजा? ऐसे नाजुक रोबोट जो किसी खास काम के लिए बने थे और कप को अपनी जगह से जरा सा हटाने पर ही फेल हो जाते थे।
ओपन-डेटा का यह नया दौर उस रुकावट को जड़ से खत्म कर रहा है:
- एंट्री की बाधाएं कम होना: अब किसी नए स्टार्टअप को काम शुरू करने के लिए करोड़ों रुपये के हार्डवेयर सेटअप की जरूरत नहीं है। वे अलग-अलग रोबोट्स और वातावरणों का टेराबाइट्स डेटा डाउनलोड कर सकते हैं और अपने मॉडल्स को ट्रेन कर सकते हैं।
- बेंचमार्किंग में तेजी: साझा डेटासेट्स के साथ, अब पूरी इंडस्ट्री अलग-अलग तरीकों की तुलना एक ही धरातल पर कर सकती है। यह असली टैलेंट को शोर से अलग करता है और उन एल्गोरिदम को बढ़ावा देता है जो असल दुनिया की जटिलताओं को झेल सकें।
- फ्लाईव्हील इफेक्ट (Flywheel Effect): जितना अधिक हाई-क्वालिटी डेटा होगा, उतने ही बेहतर ‘फाउंडेशन मॉडल्स’ बनेंगे। बेहतर मॉडल्स से अधिक एडवांस एप्लिकेशन बनेंगे, जो बदले में और भी ज्यादा और दिलचस्प डेटा पैदा करेंगे। यही वह चक्र है जो रोबोटिक्स को लैब से निकालकर हमारे घरों और दफ्तरों तक पहुँचाएगा।
रोबोटिक्स का भविष्य उस कंपनी से तय नहीं होगा जिसके पास सबसे चमक-धमक वाला हार्डवेयर है, बल्कि उस इकोसिस्टम से तय होगा जिसके पास सबसे समृद्ध और विविधतापूर्ण डेटा है। नाचते हुए ह्युमनॉइड्स वीडियो में देखने में भले ही अच्छे लगें, लेकिन साझा डेटासेट्स की यह खामोश और तेज ग्रोथ ही वह असली बुनियाद है जिस पर भविष्य टिका है। सॉफ्टवेयर की दुनिया को बदलने वाली ओपन-सोर्स क्रांति अब भौतिक दुनिया (physical world) में दस्तक दे चुकी है, और यह बदलाव एक-एक डेटासेट के साथ अपनी जगह बना रहा है।