
Google DeepMind vient de lever le voile sur Gemini Robotics-ER 1.6, la toute dernière itération de son modèle de “raisonnement incarné” (Embodied Reasoning), conçue pour injecter aux robots une bonne dose de ce bon sens si crucial pour appréhender le monde physique. Cette nouvelle mouture décuple significativement la capacité d’un robot à voir, comprendre et interagir avec son environnement, le propulsant bien au-delà de la simple exécution d’ordres préprogrammés pour le faire véritablement raisonner sur ses tâches.
Au cœur de cette mise à jour de Gemini Robotics-ER 1.6, on trouve une compréhension visuelle et spatiale affûtée, illustrée de manière éclatante par sa nouvelle capacité à “pointer du doigt”. Demandez-lui de dénicher un outil précis dans un atelier en désordre, et le modèle est désormais capable d’identifier, de compter et de localiser avec une précision chirurgicale les éléments pertinents, tout en ignorant les intrus. Ce n’est pas seulement une question de détection ; c’est la pierre angulaire d’une logique spatiale bien plus complexe, comme l’élaboration de trajectoires pour une préhension parfaite ou la compréhension d’instructions relationnelles du type “déplace la clé à molette dans la boîte à outils”. Le modèle peut même raisonner sur des contraintes, par exemple en identifiant tous les objets suffisamment petits pour tenir dans un conteneur désigné.
Le modèle s’attaque également à un défi chronique en robotique : savoir quand une tâche est réellement achevée. Grâce à un raisonnement multi-vue avancé, Gemini Robotics-ER 1.6 peut fusionner les flux vidéo en direct de plusieurs caméras – par exemple, une caméra zénithale et une autre fixée au poignet – pour construire une image complète de la scène. Cela évite qu’un robot ne se retrouve bloqué dans une boucle ou n’échoue une tâche simplement parce qu’un objet est temporairement masqué d’un point de vue.
Pourquoi est-ce si crucial ?
Cette mise à jour est bien plus qu’une simple amélioration incrémentale des performances ; il s’agit de poser les bases des compétences fondamentales pour l’autonomie. La capacité à lire des cadrans analogiques, à fusionner plusieurs flux de caméras et à comprendre des relations spatiales complexes, voilà ce qui distingue un bras robotisé d’usine d’un robot de terrain véritablement utile. Selon l’annonce officielle de DeepMind, il s’agit de leur modèle robotique le plus sûr à ce jour.
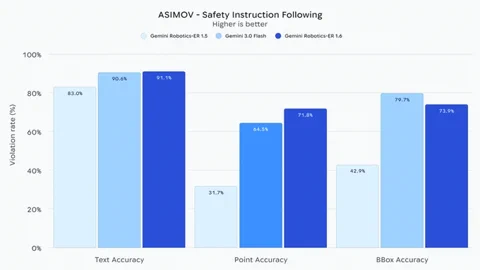
Et c’est peut-être le plus crucial : Gemini Robotics-ER 1.6 démontre une “capacité considérablement améliorée” à respecter les contraintes de sécurité physiques. Il comprend des instructions comme éviter les liquides ou ne pas soulever d’objets de plus de 20 kg. Comparé au modèle de référence Gemini 3.0 Flash, il serait 10 % plus performant dans la perception des risques de blessures humaines dans les vidéos. Cette focalisation sur la sécurité et le raisonnement en situation réelle est une étape cruciale vers des robots capables de fonctionner de manière fiable et sûre dans des environnements humains imprévisibles. Le modèle est déjà accessible aux développeurs via l’API Gemini et Google AI Studio.
