
Google DeepMind has unveiled Gemini Robotics-ER 1.6, the latest update to its “Embodied Reasoning” model, designed to give robots a much-needed dose of common sense about the physical world. The new model significantly improves a robot’s ability to see, understand, and interact with its surroundings, moving beyond just following rote commands to actually reasoning about its tasks.
A core upgrade in Gemini Robotics-ER 1.6 is its enhanced visual and spatial understanding, best exemplified by its “pointing” capability. Ask it to find a specific tool in a cluttered workshop, and the model can now accurately identify, count, and pinpoint the correct items while ignoring irrelevant objects. This isn’t just about finding things; it’s a foundation for more complex spatial logic, like mapping trajectories for the perfect grasp or understanding relational commands like “move the wrench to the toolbox.” The model can even reason through constraints, such as identifying every object small enough to fit inside a designated container.
The model also tackles a chronic robotics challenge: knowing when a job is actually finished. Thanks to advanced multi-view reasoning, Gemini Robotics-ER 1.6 can fuse live video streams from multiple cameras—say, an overhead and a wrist-mounted one—to build a complete picture of the scene. This prevents a robot from getting stuck in a loop or failing a task simply because an object is temporarily occluded from one viewpoint.
Why is this important?
This update is more than an incremental bump in performance; it’s about building the foundational skills for autonomy. The ability to read analog gauges, fuse multiple camera feeds, and understand complex spatial relationships is what separates a factory arm from a useful field robot. According to DeepMind’s official announcement, this is their safest robotics model yet.
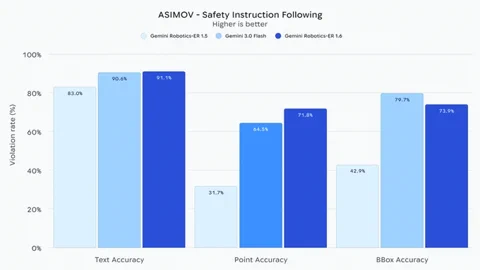
Perhaps most critically, Gemini Robotics-ER 1.6 shows a “substantially improved capacity” to adhere to physical safety constraints. It understands instructions like avoiding liquids or not lifting items over 20kg. Compared to the baseline Gemini 3.0 Flash model, it’s reportedly 10% better at perceiving human injury risks in videos. This focus on safety and real-world reasoning is a crucial step toward robots that can operate reliably and safely in unpredictable human environments. The model is already available to developers through the Gemini API and Google AI Studio.
