
Just when you thought your phone’s camera was only good for blurry concert photos, researchers have turned it into a real-time 3D scanner. Robbyant, the embodied AI division of Ant Group, has just open-sourced LingBot-Map, a new 3D foundation model that reconstructs detailed, large-scale environments from a single streaming video. The kicker? It does this at a brisk 20 frames per second, a speed that makes most traditional photogrammetry methods look like they’re wading through molasses.
The secret sauce is a novel architecture called a Geometric Context Transformer (GCT). This isn’t just another transformer bolted onto a vision problem. The GCT is specifically designed to tackle the Achilles’ heel of monocular (single-camera) SLAM systems: drift. It cleverly manages geometric information using three parallel attention mechanisms: an anchor context for stable coordinate grounding, a local pose-reference window for fine-grained detail, and a trajectory memory to correct for errors over long distances. This allows LingBot-Map to process sequences exceeding 10,000 frames with what Robbyant claims is “almost unchanged accuracy.” The project is available now on GitHub. Hyperlink: Robbyant/lingbot-map
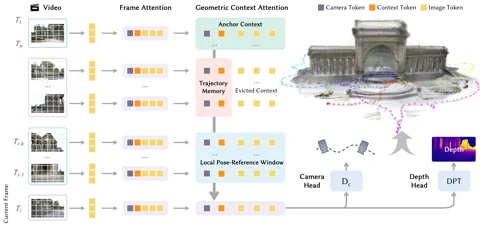
The performance claims are, frankly, audacious. On the challenging Oxford Spires dataset, LingBot-Map achieved an Absolute Trajectory Error of just 6.42 meters, a nearly 2.8x improvement over the previous best streaming method. It even outperforms established offline methods that have the luxury of processing all images at once. On the ETH3D benchmark, it scored an F1 of 98.98, obliterating the runner-up by over 21 percentage points. For those interested in the gory technical details, the full methodology is laid out in a paper on arXiv. Hyperlink: Read the paper on arXiv
Why is this important?
LingBot-Map represents a significant step toward democratizing spatial intelligence. By eliminating the need for expensive LiDAR or complex multi-camera rigs, it opens the door for low-cost, high-performance 3D perception in robotics, autonomous vehicles, and augmented reality. This isn’t just about making pretty point clouds; it’s about giving machines a continuous, real-time understanding of the physical world. As a “3D foundation model,” it’s part of a larger trend to build AI that doesn’t just process text or images, but perceives, navigates, and interacts with complex, unstructured environments—a cornerstone for the future of embodied AI.
