
Let’s talk about the elephant in the cleanroom. While venture capitalists trip over themselves to fund the next bipedal wonder, a quiet and damning truth is hiding in plain sight: for all the billions invested, the total useful work performed by this new wave of advanced robots is, to put it charitably, a rounding error.
In a recent, brutally honest dispatch, Dyna Co-Founder Yang York took a scalpel to the hype, and the picture he paints is not pretty. Forget the slick demo videos of robots doing parkour or delicately handling an egg. The real story is in the numbers, and they tell a tale of profound disconnect. Between 2022 and 2025, the robotics industry vacuumed up over $18 billion in funding. Yet, as of early 2026, the real-world impact remains infinitesimally small.
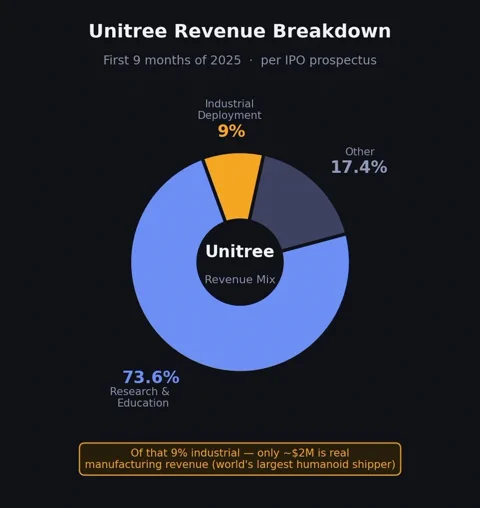
York points to the poster children of the hardware boom. Tesla’s Elon Musk admitted on a January 2026 earnings call that effectively zero Optimus robots were doing useful work in his factories. And Unitree, arguably the world’s largest shipper of humanoids, revealed in its March IPO prospectus that a staggering 73.6% of its revenue came from research and education sales. Actual industrial deployment? A mere 9%, most of which was “enterprise reception and tour-guide” duty. The revenue from real manufacturing tasks was a paltry ~$2 million.
This chasm between financial expectation and physical reality is what York calls the bubble. And it’s not about whether the tech will eventually work. It’s about the timeline. As he puts it, “A bubble is the gap between current technical capability and human expectations, multiplied by time.”
Your LLM Analogy is Bad and You Should Feel Bad
A core tenet of York’s argument is that the robotics industry is high on the wrong supply, namely, bad analogies. Investors and founders, drunk on the exponential growth of Large Language Models, are trying to apply the same playbook to a world of atoms, and it’s failing spectacularly.
LLMs scaled at lightning speed because they are pure software, distributed instantly to billions via the internet. Robots, however, are physical. They break. They need maintenance. They have to navigate the messy, unpredictable chaos of the real world.
The more tempting, and equally flawed, analogy is the autonomous vehicle (AV) industry. But even that doesn’t fit. A car is useful even without self-driving; it’s an established product category, a distribution channel waiting for an AI upgrade. A non-intelligent humanoid, York quips, is “a 60-pound machine with 28 degrees of freedom and no purpose.” It has no built-in user base. There is no installed base to upgrade. The industry is trying to build the app, the phone, and the cell network all at once.
This means robotics will not have an LLM-shaped takeoff curve. It won’t even have an AV-shaped curve. It will have a robotics-shaped curve, and the industry’s refusal to accept this is its most expensive mistake.
The Three Great Deceptions of Modern Robotics
York identifies three core fallacies that are propping up the hype bubble. These are the sweet little lies the industry tells itself as it cashes another nine-figure check.
1. Hardware is Not a Channel
The most expensive misconception is that shipping a physical robot is the same as building a distribution channel. The logic goes: get the hardware into a customer’s facility, and the rest will follow. This is a fatal error.
A real channel creates recurring value. If a robot performs a demo and then gathers dust because it can’t meet the ROI bar, you don’t have a channel. You have a very expensive paperweight. York argues a true robotics channel is a full-stack deployment system: site assessment, task definition, data capture, remote debugging, and continuous updates.
“The test of a channel is whether the next deployment is faster than the last one,” York writes. “If it is not, you have not built a channel. You have built inventory and PR.”

2. Your “Foundation Model” is Mostly Foundation
The second error is a misunderstanding of how AI models actually get good. The entire conversation in robotics has been about pre-training on massive datasets. But the secret sauce of modern LLMs isn’t just pre-training; it’s the tight, iterative loop between pre-training and domain-specific, post-training feedback.
Robotics has barely begun this loop. Most teams are force-feeding models with more data, praying that capability emerges. But without the post-training signal from real-world deployments—from robots actually failing on a factory floor—the models can’t mature. There’s no unified metric like an LLM’s “perplexity” to optimize against. A model that aces a benchmark in a lab is useless if it can’t handle the lighting changes in a real warehouse.
3. The Flywheel is Made of Boring Stuff
This leads to the most underestimated part of the stack: the deployment infrastructure itself. This isn’t just sales; it’s the gritty, unglamorous engineering work of turning a one-off deployment into a reusable, compounding asset. It’s the tooling for remote diagnostics, data routing, and reliable updates.
Without this “flywheel,” the whole system seizes up. The robot doesn’t get into real environments. The model doesn’t get the real-world data it needs to improve. The capability curve flattens, no matter how much compute you throw at it. The bubble, York argues, “lives in the gap between teams that have understood this and teams still optimizing for benchmark numbers and demo videos.”
The Only Way Out is Through
Faced with this reality, the field has split. Some are model-first, betting that a powerful enough “brain” will solve the problem and hardware will become a commodity. Others are hardware-first, believing the perfect body is the key and open-source software will fill the gaps.
York and Dyna are firmly in the third camp: vertical integration. They didn’t choose it because it’s trendy; they chose it because, after a year of deploying their DYNA-1 model, they found the alternative to be impossible. They learned the hard way that deployment doesn’t just magically get easier. The feedback loop has to close across research, hardware, and deployment simultaneously.
This is the work ahead. It’s not about chasing the next viral demo. It’s about the painstaking process of building a system that makes the tenth deployment faster and more reliable than the first. The first team to truly crack that code won’t just win the market—they’ll define it. Until then, we’re all just watching a very expensive science fair.
