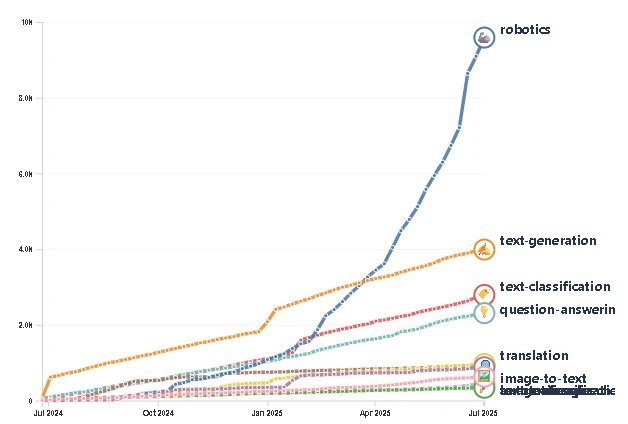
If you think the biggest story in robotics right now is a bipedal robot not falling over, you’re looking in the wrong direction. Something far more seismic is happening, not in the hardware labs, but in the data logs. A revolution is underway, hiding in plain sight on platforms like Hugging Face, and it’s powered by an exponential explosion of open-source data.
While large language models have been feasting on the open internet for years, robots have been starved. They don’t learn from text; they learn from the messy, chaotic reality of the physical world—video feeds, joint actions, sensor streams, and, most importantly, failures. Historically, this precious data was the crown jewel of robotics companies, locked away in proprietary vaults. That era is decisively over. In just the last year, the number of robotics datasets on Hugging Face has catapulted from 1,145 to nearly 27,000. That’s a 2,400% increase, rocketing the category from 44th place to number one in just three years, blowing past text generation, which sits at a mere 5,000 datasets.
The Data Deluge
This isn’t just a collection of hobbyist projects. The chart, courtesy of tech analyst Pierre-Alexandre Balland, illustrates a Cambrian explosion of shared robotic knowledge. The data is filtered to only include datasets with over 200 downloads, indicating that this vast repository is being actively used for experimentation and model training.

This surge is the result of a perfect storm: cheaper storage, better tooling, and the open-source ethos of the AI world finally bleeding over into hardware. Platforms like Hugging Face have radically lowered the friction of sharing, enabling a collaborative ecosystem that was unthinkable five years ago. Initiatives like LeRobot aim to standardize formats and tools, making it easier for everyone to contribute and benefit from shared data.
The New Data Barons
So, who is opening the floodgates? While you might know NVIDIA for its GPUs, it’s rapidly becoming a dominant force in robotics data. In 2025 alone, NVIDIA’s open datasets were downloaded over 9 million times. Their datasets for post-training the Isaac GR00T generalist robot model are the most downloaded on the entire platform, with 7.9 million downloads in the past year. This isn’t charity; it’s a strategic move to build the foundational infrastructure for the entire field, ensuring their hardware remains at the center of the ecosystem.
But they’re not alone. The leaderboard of data contributors reads like a who’s who of global AI powerhouses:
- Shanghai AI Lab follows closely with an astonishing 7.6 million downloads.
- Hugging Face itself, through its own initiatives, accounts for 1.4 million.
- Academic hubs like Stanford Vision and Learning Lab (SVL) have contributed datasets with over 710,000 downloads.
- Other major players include AgiBot, Yaak AI, AllenAI, and even hardware makers like Unitree Robotics.

Why This Is the Real Revolution
For decades, progress in robotics was hamstrung by a simple, brutal reality: every lab had to reinvent the wheel. Building a robot that could pick up a cup required a team of PhDs, a custom robot, and thousands of hours of painstaking data collection. The result? Brittle, task-specific machines that failed the moment you moved the cup two inches to the left.
This open-data paradigm shatters that bottleneck.
- Lowering the Barrier to Entry: A startup with a novel learning algorithm no longer needs a multi-million dollar hardware setup to get started. They can download terabytes of real-world data from a dozen different robots and environments to train and validate their models.
- Accelerating Benchmarking: With shared datasets, the entire field can now compare different approaches on a level playing field. It separates the signal from the noise, rewarding algorithms that generalize well across diverse, messy, real-world conditions.
- Creating a Flywheel Effect: More high-quality data leads to better foundation models. Better models enable more sophisticated applications, which in turn generate more, and more interesting, data. This virtuous cycle is the engine that will finally get robotics out of the lab and into our lives.
The future of robotics won’t be defined by the company with the most polished hardware, but by the ecosystem with the richest and most diverse data. While dancing humanoids make for great videos, the quiet, exponential growth of shared datasets is the real infrastructure being built. The open-source revolution that transformed software is finally here for the physical world, and it’s happening one dataset at a time.