
Google DeepMind hat mit Gemini Robotics-ER 1.6 das neueste Update seines „Embodied Reasoning“-Modells vorgestellt. Das Ziel: Robotern endlich die nötige Portion gesunden Menschenverstand für die physische Welt zu verpassen. Das neue Modell verbessert die Fähigkeit einer Maschine drastisch, ihre Umgebung nicht nur zu sehen, sondern sie wirklich zu verstehen und mit ihr zu interagieren. Damit lässt der Bot das reine Abarbeiten sturer Befehlsketten hinter sich und beginnt, über seine Aufgaben aktiv nachzudenken.
Ein Herzstück des Upgrades ist das geschärfte visuelle und räumliche Verständnis, das besonders durch die neue „Pointing“-Funktion glänzt. Bittet man den Roboter, ein bestimmtes Werkzeug in einer völlig chaotischen Werkstatt zu finden, kann das Modell die korrekten Gegenstände nun präzise identifizieren, zählen und lokalisieren – während es den irrelevanten Kram einfach ignoriert. Das ist weit mehr als bloße Objekterkennung; es ist das Fundament für komplexe räumliche Logik. So kann der Roboter Trajektorien für den perfekten Griff berechnen oder relationale Befehle wie „Leg den Schraubenschlüssel in den Werkzeugkoffer“ korrekt umsetzen. Das Modell kann sogar logische Einschränkungen abwägen, etwa indem es nur jene Objekte identifiziert, die klein genug für einen bestimmten Behälter sind.
Zudem knöpft sich das Modell eine der größten Herausforderungen der Robotik vor: zu erkennen, wann ein Job wirklich erledigt ist. Dank fortschrittlichem „Multi-View Reasoning“ kann Gemini Robotics-ER 1.6 Live-Videostreams von mehreren Kameras gleichzeitig fusionieren – zum Beispiel von einer Deckenkamera und einer Kamera direkt am Greifer. Das verhindert, dass ein Roboter in einer Endlosschleife hängen bleibt oder an einer Aufgabe scheitert, nur weil ein Objekt aus einem bestimmten Blickwinkel kurzzeitig verdeckt ist.
Warum ist das ein Meilenstein?
Dieses Update ist kein bloßer inkrementeller Performance-Schub; es geht darum, die Basisfähigkeiten für echte Autonomie zu schaffen. Die Fähigkeit, analoge Messgeräte abzulesen, verschiedene Kamera-Feeds zu kombinieren und komplexe räumliche Zusammenhänge zu begreifen, ist genau das, was einen simplen Fabrikarm von einem nützlichen Roboter für den Feldeinsatz unterscheidet. Laut der offiziellen Ankündigung von DeepMind handelt es sich zudem um ihr bisher sicherstes Robotik-Modell.
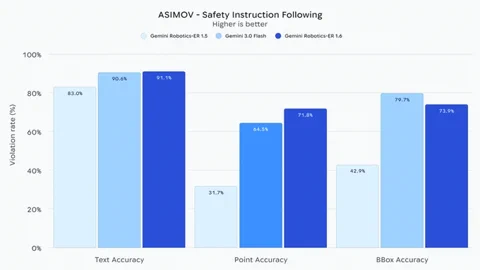
Besonders kritisch: Gemini Robotics-ER 1.6 zeigt eine „erheblich verbesserte Kapazität“, physische Sicherheitsvorgaben einzuhalten. Das Modell versteht Anweisungen wie das Meiden von Flüssigkeiten oder das Limit, keine Gegenstände über 20 kg zu heben. Im Vergleich zum Basismodell Gemini 3.0 Flash ist es Berichten zufolge um 10 % besser darin, potenzielle Verletzungsrisiken für Menschen in Videos zu erkennen. Dieser Fokus auf Sicherheit und logisches Denken in der realen Welt ist ein entscheidender Schritt hin zu Robotern, die zuverlässig und sicher in unvorhersehbaren menschlichen Umgebungen agieren können. Das Modell ist für Entwickler bereits über die Gemini API und Google AI Studio verfügbar.
