
Gerade als man dachte, die Smartphone-Kamera sei lediglich für verwackelte Konzertfotos und Essensbilder gut, verwandeln Forscher sie in einen waschechten Echtzeit-3D-Scanner. Robbyant, die auf Embodied AI spezialisierte Sparte der Ant Group, hat soeben LingBot-Map als Open Source veröffentlicht – ein neues 3D-Foundation-Modell, das detaillierte, großflächige Umgebungen aus einem simplen Videostream rekonstruiert. Der Clou: Das System arbeitet mit geschmeidigen 20 Bildern pro Sekunde (FPS) und lässt damit herkömmliche Photogrammetrie-Methoden so alt aussehen, als würden sie versuchen, im Tiefschnee zu rennen.
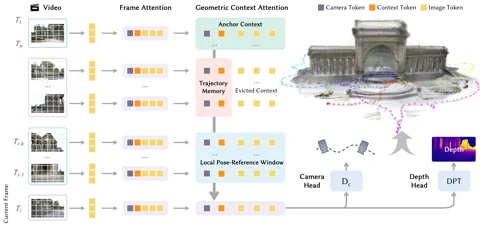
Das Geheimrezept ist eine neuartige Architektur namens Geometric Context Transformer (GCT). Hierbei handelt es sich nicht einfach um einen weiteren Transformer, der lieblos auf ein Bildverarbeitungsproblem geklatscht wurde. Der GCT wurde gezielt entwickelt, um die Achillesferse monokularer SLAM-Systeme (Single-Camera) auszumerzen: den Drift. Durch drei parallele Attention-Mechanismen wird die geometrische Information clever verwaltet: Ein „Anchor Context“ sorgt für eine stabile Koordinatenverankerung, ein lokales Posen-Referenzfenster kümmert sich um die feinen Details und ein Trajektorien-Speicher korrigiert Fehler über lange Distanzen hinweg. Dadurch kann LingBot-Map Sequenzen von mehr als 10.000 Einzelbildern verarbeiten, wobei die Genauigkeit laut Robbyant „nahezu unverändert“ bleibt. Das Projekt steht ab sofort auf GitHub bereit. Hyperlink: Robbyant/lingbot-map
Die Performance-Versprechen sind, offen gesagt, ziemlich kühn. Im anspruchsvollen Oxford-Spires-Datensatz erreichte LingBot-Map einen „Absolute Trajectory Error“ von gerade einmal 6,42 Metern – eine fast 2,8-fache Verbesserung gegenüber der bisher besten Streaming-Methode. Das System schlägt sogar etablierte Offline-Methoden, die den Luxus haben, alle Bilder gleichzeitig verarbeiten zu können. Im ETH3D-Benchmark erzielte es einen F1-Score von 98,98 und pulverisierte den Zweitplatzierten mit einem Vorsprung von über 21 Prozentpunkten. Wer tief in die technischen Eingeweide der Methodik abtauchen möchte, findet alle Details im entsprechenden Paper auf arXiv. Hyperlink: Das Paper auf arXiv lesen
Warum ist das wichtig?
LingBot-Map markiert einen entscheidenden Schritt in Richtung der Demokratisierung räumlicher Intelligenz. Da keine teuren LiDAR-Sensoren oder komplexen Multi-Kamera-Setups mehr nötig sind, ebnet das Modell den Weg für kostengünstige, hochperformante 3D-Wahrnehmung in der Robotik, bei autonomen Fahrzeugen und in der Augmented Reality. Hier geht es nicht nur darum, hübsche Punktwolken zu generieren; es geht darum, Maschinen ein kontinuierliches Echtzeit-Verständnis der physischen Welt zu ermöglichen. Als „3D-Foundation-Modell“ ist es Teil eines größeren Trends: KI soll nicht mehr nur Texte oder Bilder verarbeiten, sondern komplexe, unstrukturierte Umgebungen wahrnehmen, darin navigieren und mit ihnen interagieren – ein absoluter Eckpfeiler für die Zukunft der Embodied AI.
