Jahrelang war die große Vision einer KI, die sich selbst verbessert, größtenteils auf die digitalen Sandkästen von Simulationen beschränkt. Es ist eine Sache, wenn eine KI ein Videospiel meistert; es ist eine völlig andere, wenn man sie an teure Hardware in der unerbittlich chaotischen realen Welt lässt. Jetzt haben Forscher von NVIDIA in Zusammenarbeit mit der Carnegie Mellon University und der UC Berkeley beschlossen, der KI die Schlüssel zum Labor zu übergeben. Ihr neues Framework namens ENPIRE erschafft im Grunde ein selbstlaufendes Roboter-Forschungsprogramm – und die ersten Ergebnisse sind ebenso beeindruckend wie beunruhigend für menschliche Robotik-Ingenieure.
ENPIRE erlaubt es „agentischer“ KI – Coding-Agenten, die autonom denken und handeln können –, die volle Kontrolle über den physischen Lernprozess zu übernehmen. Das System erreichte eine verblüffende Erfolgsquote von 99 % bei komplexen Manipulationsaufgaben, die normalerweise wochenlanges menschliches Ausprobieren erfordern würden: das Einsetzen von Pins in eine Box, das Einbauen einer GPU oder sogar das Durchtrennen eines Kabelbinders mit einem Werkzeug. Hier geht es nicht nur darum, ein paar Hyperparameter zu optimieren; die KI-Agenten schreiben ihre eigenen Algorithmen auf Basis von Echtwelt-Ergebnissen um und lagern so den gesamten Forschungs- und Entwicklungszyklus effektiv an sich selbst aus.
Der automatisierte Feedback-Loop
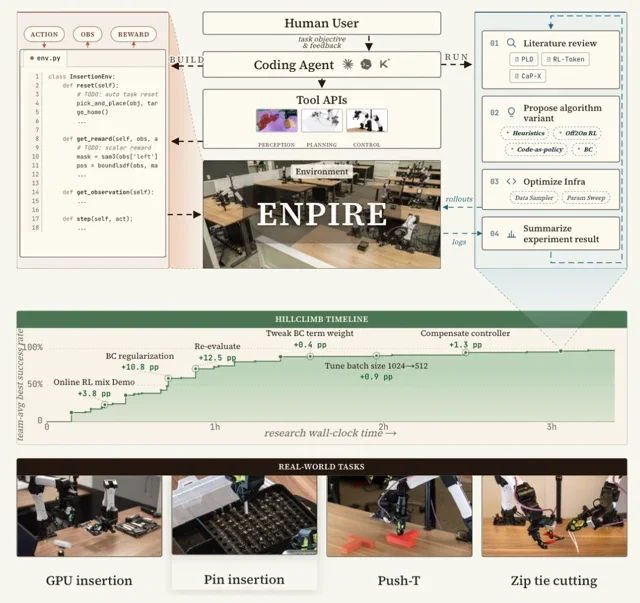
Der zentrale Flaschenhals in der Robotik war schon immer der mühsame Prozess der menschlichen Überwachung und des algorithmischen Engineerings. ENPIRE packt dieses Problem an der Wurzel, indem es einen geschlossenen, wiederholbaren Feedback-Loop schafft, den eine KI völlig eigenständig verwalten kann. Das Framework ist in vier kluge Module unterteilt, die ihm seinen Namen geben:
- Environment (EN): Dieses Modul automatisiert die zwei nervigsten Teile von Praxistests: das Zurücksetzen der Szenerie für den nächsten Versuch und die Verifizierung des Ergebnisses. Bevor die KI überhaupt mit der Hauptaufgabe beginnt, findet ein anderer Agent heraus, wie der Arbeitsbereich automatisch resettet werden kann – wobei die Erkenntnis hilft, dass das Zurücksetzen oft ein einfacheres Robotik-Problem ist als die eigentliche Aufgabe.
- Policy Improvement (PI): Hier machen sich die KI-Agenten an die Arbeit. Sie können eine breite Palette von Strategien vorschlagen und implementieren, um besser zu werden – vom Schreiben einfacher Heuristiken bis hin zum Einsatz komplexer Methoden wie Behavior Cloning oder Reinforcement Learning (RL).
- Rollout (R): Hier trifft das Metall auf die Realität. Das Modul führt die vom Agenten vorgeschlagene Strategie auf einem oder mehreren physischen Robotern aus und sammelt wertvolle Echtzeitdaten.
- Evolution (E): Die KI-Agenten analysieren die Protokolle der Rollouts, konsultieren wissenschaftliche Literatur nach neuen Ideen und verfeinern dann den Code für die nächste Iteration. Es ist eine unermüdliche, automatisierte Version der wissenschaftlichen Methode, die rund um die Uhr läuft.
Diese Struktur verwandelt den chaotischen Prozess des Roboter-Lernens in der echten Welt in ein sauberes, kontrollierbares Optimierungsproblem, das nach dem ersten Setup kaum noch menschliches Eingreifen erfordert.

Vom Praktikanten zum Forschungsleiter
Was ENPIRE zu einem signifikanten Sprung macht, ist das Maß an Autonomie, das der KI zugestanden wird. NVIDIA-Forscher Jim Fan nennt dies „echte Autoresearch“. Die Agenten drehen nicht bloß an den Reglern eines vorgefertigten Algorithmus. Sie erforschen aktiv verschiedene Programmierparadigmen, schreiben ihre eigenen Trainingsziele um und modifizieren sogar die Data-Loader.
In einem Fall entschied ein Agent während des Erlernens einer Pin-Insertion-Aufgabe eigenständig, dass das Tuning von RL-Parametern nicht der beste Weg sei. Stattdessen schrieb er von Grund auf einen eigenen Kontaktkraft-Sicherheitscontroller, der sich als wesentlich effektivere Lösung erwies. Das ist das KI-Äquivalent zu einem Forschungs-Praktikanten, der sich selbst zum Chef-Wissenschaftler befördert und dann ein Problem löst, an dem die erfahrenen Kollegen festgebissen hatten.
Die „Hillclimb-Timeline“ des Projekts visualisiert diesen Prozess eindrucksvoll: Sie zeigt, wie verschiedene von Agenten vorgeschlagene Ideen – wie das Hinzufügen von Regularisierung oder die Kompensation des Controllers – die Erfolgsquote in nur wenigen Stunden schrittweise in Richtung der fast perfekten 99-Prozent-Marke treiben.
Skalierung der Roboter-Belegschaft
ENPIRE ist auf Skalierbarkeit ausgelegt. Das Framework kann eine ganze Flotte von Robotern parallel steuern, was den Lernprozess dramatisch beschleunigt. Um die Effizienz dieses Multi-Roboter-Multi-Agenten-Systems zu quantifizieren, schlugen die Forscher zwei neue Metriken vor: Mean Robot Utilization (MRU) und Mean Token Utilization (MTU). Diese messen, wie effektiv das System die Roboter beschäftigt hält und wie effizient es das Rechenbudget des KI-Modells nutzt.
Das Versprechen dieser Forschung ist tiefgreifend. Durch die Automatisierung des physischen Feedback-Loops könnte sich der Flaschenhals in der Robotik verschieben: Weg vom mühsamen Design von Algorithmen, hin zum Design von abgeschlossenen, sich selbst zurücksetzenden Umgebungen, die KI-Agenten dann im Alleingang erobern.
NVIDIA hat angekündigt, das gesamte ENPIRE-Framework als Open Source zur Verfügung zu stellen, was den Zugang zu fortschrittlicher Robotikforschung demokratisieren könnte. Bald könnte jeder mit einem Roboterarm und einer ordentlichen GPU in der Lage sein, sein eigenes, sich selbst optimierendes Roboterlabor zu Hause einzurichten. Die Ära, in der die KI sich in der realen Welt selbst unterrichtet, ist keine Simulation mehr – sie läuft live, schneidet Kabelbinder durch und schreibt ihren eigenen Code für den Job um.
Tiefergehende technische Details finden Sie im vollständigen Paper. Hyperlink: Lesen Sie das Paper auf der NVIDIA Research Seite.